L04 Procedures and MMIO
MIT 6.004 2019 L04 Procedures and MMIO,由Silvina Hanono Wachman讲述。
本讲座深入讲解了汇编语言中程序(Procedures)的处理,尤其是关于参数传递、内存访问以及更复杂例子的实现。
主要内容
- 程序和内存操作回顾
- 回顾了程序处理中的关键概念,如参数传递、返回值、局部变量和程序退出点。
- 强调了使用栈(Stack)和激活记录(Activation Record)来管理程序调用所需的信息。
- 激活记录 活动记录(Activation Record),常称栈帧(stack frame)。
- 内存操作详解
- 详细区分了加载(Load)和存储(Store)指令与立即数加载(Load Immediate)的不同,明确了后者并不访问内存。
- 讨论了使用栈进行数据保存和恢复的具体方法,包括如何通过调整栈指针(Stack Pointer)来保存和恢复寄存器值。
- 嵌套程序和递归程序
- 介绍了嵌套程序调用中保存返回地址(Return Address)的重要性,特别是当程序中有多层调用时如何使用栈来管理这些地址。
- 通过斐波那契数列的计算示例详细展示了如何实现递归程序。
- 使用指针传递数组
- 讨论了如何通过指针而不是直接通过值来传递数组给程序,以处理大型数据结构。
- 通过查找数组中的最大值的示例演示了如何在程序中使用指针和内存访问来处理数组数据。
- 内存布局和MMIO
- 解释了内存的不同区域(如栈、堆、静态区和代码区)以及它们的用途。
- 简要介绍了内存映射I/O(Memory-Mapped I/O,MMIO)的概念,为后续实验室内容预设背景。
- 参数传递的选择和优化
- 讨论了何时选择直接传递值与何时使用指针传递参数的考量,特别是在参数数量超出寄存器数量时的策略。
分页知识点
程序和MMIO(内存映射输入输出)
li, lui, 和mv指令与lw指令的区别
这一部分对RISC-V指令进行了澄清:
li(load immediate)和lui(load upper immediate)指令不涉及内存操作。它们是立即数加载指令,直接将常量编码到指令中:li a1, 2:将立即数2加载到寄存器a1中。li a1, 0x12345:将立即数0x12345加载到寄存器a1中。lui a1, 2:将立即数2加载到寄存器a1的上半部分。mv(move)指令也不是内存操作。它用于将一个寄存器的内容复制到另一个寄存器:mv a1, a0:将寄存器a0的内容复制到寄存器a1中。
lw和sw指令对内存的引用
这里解释了lw(load word)和sw(store word)是内存操作指令:
lw用于从内存加载一个字(32位)到寄存器。sw用于将寄存器的内容存储到内存中。
示例中展示了正确和错误的用法:
- 正确:要将
a0的结果存储到a2中,应该使用mv指令,然后用sw存储到内存。 - 错误:不能直接使用
add指令将a0的内容加到内存地址。
激活帧和过程调用的回顾
总结激活帧(activation frames)常称栈帧(stack frame)和程序调用的概念:
- 激活帧包含了程序调用的数据,例如参数、返回地址和局部或临时变量。
- 当调用程序时,在内存中分配一个新的激活帧;程序退出时,激活帧被释放。
- 激活帧以栈的方式分配,即遵循LIFO原则。
- 当前程序的激活帧总是在栈顶。
激活帧结构
编译器使用一致的栈帧约定:
- 调用过程前:栈上有未使用的空间,
sp指向栈顶。 - 过程调用期间:在栈上分配了激活帧,包括局部变量(如果有的话)、保存的寄存器(如果有的话)、保存的返回地址
ra和保存的参数寄存器(如果有的话)。 - 过程调用后:激活帧被释放,回到了只有未使用空间的状态。
使用栈的回顾
栈的内容包括:
- 推入前(Before push):栈上有未使用的空间,
sp指向栈顶。 - 推入后(After push):
ra和a0被保存在栈上,sp更新为指向新的栈顶。 - 弹出后(After pop):
ra和a0已经从栈上恢复,sp恢复为原来的位置。
示例推入(push)序列:
addi sp, sp, -8
sw ra, 0(sp)
sw a0, 4(sp)
示例弹出(pop)序列:
lw ra, 0(sp)
lw a0, 4(sp)
addi sp, sp, 8
RISC-V栈的回顾
- 栈存在于内存中,栈从高地址向低地址增长。
sp指向栈顶,即最后推入的元素。- 推入序列通常涉及减小
sp,然后用sw指令存储数据。 - 弹出序列则是用
lw指令恢复数据,随后增加sp的值。
栈的纪律:
- 可以在任何时候使用栈,但是要留下原样。
RISC-V寄存器的回顾
列出了寄存器的象征性名称、寄存器号、描述,以及是调用者(caller)还是被调用者(callee)负责保存的信息。
a0 to a7:寄存器x10至x17,用于存放函数参数。保存者是调用者(caller)。a0 and a1:寄存器x10和x11,用于存放函数的返回值。保存者也是调用者(caller)。ra:寄存器x1,用于存放函数的返回地址。保存者是调用者(caller)。t0 to t6:寄存器x5-7, x28-31,作为临时寄存器。保存者是调用者(caller)。s0 to s11:寄存器x8-9, x18-27,作为需要被保存的寄存器,以便在函数调用后恢复原值。保存者是被调用者(callee)。sp:寄存器x2,作为栈指针,指向栈顶的地址。保存者是被调用者(callee)。gp:寄存器x3,作为全局指针。tp:寄存器x4,作为线程指针。zero:寄存器x0,是一个固定的零寄存器,总是返回零值。
在设计函数和过程调用的时候,编程者需要遵循这个约定,确保正确使用每个寄存器,以及在函数调用过程中正确保存和恢复这些寄存器的值。
调用约定回顾
调用者(Caller):在函数调用之前保存ra(返回地址)寄存器到栈上,并在函数返回后恢复。如果有aN寄存器需要在过程调用后继续使用,也要进行保存和恢复。
被调用者(Callee):在使用sN寄存器之前,要先保存它们原始的值,并在函数退出前恢复。在退出函数时,还需要恢复栈指针sp到其原始值。
一个函数示例:
# 调用函数
addi sp, sp, -4
sw s0, 0(sp)
...
lw s0, 0(sp)
addi sp, sp, 4
ret
# 函数本身
func:
addi sp, sp, -4
sw s0, 0(sp)
...
lw s0, 0(sp)
addi sp, sp, 4
ret
嵌套程序调用
如果一个过程调用了另一个过程,它需要保存自己的返回地址。请记住ra是调用者保存的。
例如,一个判断两个数是否互质的函数coprimes调用了gcd函数:
coprimes:
addi sp, sp, -4
sw ra, 0(sp) # 保存 ra
call gcd # 调用 gcd
addi a0, a0, -1
sltiu a0, a0, 1
lw ra, 0(sp) # 恢复 ra
addi sp, sp, 4
ret
在这段RISC-V汇编代码中,coprimes是一个函数,其目的是调用另一个函数gcd,并使用gcd的结果来确定两个数是否互质(即最大公约数是否为1)。下面是对关键部分代码的逐行解释:
addi sp, sp, -4 # 在栈上分配4字节空间
sw ra, 0(sp) # 将ra(返回地址)保存到栈上
call gcd # 调用gcd函数
addi a0, a0, -1 # 将gcd函数的返回值(存储在a0)减1
sltiu a0, a0, 1 # 检查a0是否小于1(无符号比较),并将结果存入a0
lw ra, 0(sp) # 从栈上恢复ra(返回地址)
addi sp, sp, 4 # 释放栈上的空间
ret # 返回到调用函数的地方
具体到addi a0, a0, -1和sltiu a0, a0, 1这两行:
addi a0, a0, -1:这行代码将寄存器a0中的值减去1。因为a0在调用gcd之后包含gcd的返回值,如果gcd返回的是1(意味着两个数互质),那么执行这条指令后a0将变成0。sltiu a0, a0, 1:这条指令进行无符号的比较。它检查寄存器a0中的值是否小于1,并将比较结果设置为1或0,存入a0中。这样,如果gcd返回的是1(两个数互质),上一条指令会将a0减到0,然后这条指令将a0设置为1,反之如果gcd返回不是1(不互质),a0已经是非零值,这条指令将a0设置为0。
总结来说,这两条指令一起用来检查gcd函数返回的是否是1。如果是1,说明输入的两个数互质,a0将被设置为1,表示真;如果不是1,说明不互质,a0将被设置为0,表示假。这个结果将作为coprimes函数的返回值。
这种实现的一个原因可能是作者希望确保coprimes函数返回的是一个明确的布尔值1或0,而不仅仅是依赖gcd可能返回的任何非1值。虽然直接与2比较也可以达到检测互质的效果,但这样做不会得到一个明确的布尔值。例如:
- 如果
gcd返回2,那么sltiu a0, a0, 2将会把a0设置为0,因为2不小于2。 - 但如果
gcd返回的是任何大于2的值,sltiu a0, a0, 2依然会将a0设置为0,这不会告诉你gcd的确切返回值,只告诉你它不是1。
在某些编程实践中,为了代码的清晰性和一致性,作者可能更偏好返回明确的布尔值。所以通过这种方式减1然后比较是否小于1,可以保证无论gcd返回什么,coprimes的返回值总是一个确切的布尔标志。
递归程序
递归程序可以看作是嵌套程序的一个特例。例如,一个计算斐波那契数的递归函数:
计算第n个斐波那契数的伪代码:
# 假设 n > 0
# 如果 n 为 0 或 1,返回 n
# 否则,返回 fib(n-1) + fib(n-2)
# 这里指令的顺序对于程序的正确行为非常关键
fib:
li t0, 2
blt a0, t0, fib_done
addi sp, sp, -8
sw s0, 0(sp) # 保存 s0
mv s0, a0 # 保存 n
call fib # 计算 fib(n-1)
mv s1, a0 # 保存 fib(n-1)
addi a0, s0, -2
call fib # 计算 fib(n-2)
add a0, s0, a0
lw s0, 0(sp) # 恢复 s0
addi sp, sp, 8
fib_done:
这段代码是一个实现斐波那契数列的递归函数,我们逐行解释如下:
li t0, 2:将临时寄存器t0加载为常数2。blt a0, t0, fib_done:如果寄存器a0(包含当前fib调用的参数n)小于2,则跳转到fib_done标签。这实现了函数的基础情况:如果n为0或1,则不需要递归,函数可以直接返回n的值。addi sp, sp, -8:分配8字节的堆栈空间来保存寄存器(因为每个寄存器都是64位,即8字节)。sw s0, 0(sp):将保存的寄存器s0的当前值存储在栈上。这是因为s0将在此函数的递归调用中被用作临时寄存器。mv s0, a0:将当前的n值(斐波那契数列中的位置),从a0移动到s0,以便后续调用fib。call fib:递归调用fib(n-1)。mv s1, a0:将递归调用返回的结果fib(n-1),从a0移动到另一个保存寄存器s1中。addi a0, s0, -2:准备下一个递归调用的参数,计算n-2并存入a0。call fib:递归调用fib(n-2)。add a0, s0, a0:将fib(n-1)和fib(n-2)的结果相加。这时s0包含fib(n-1)的值,a0包含fib(n-2)的结果。结果存回a0,为返回值做准备。lw s0, 0(sp):从栈中恢复保存的寄存器s0的值。addi sp, sp, 8:将栈指针sp移回之前的位置,反向执行步骤3的操作,释放之前分配的栈空间。fib_done:如果a0小于2,就跳转到这里。在此标签处,简单返回a0(在递归调用的基础情况中,它包含n的值,即0或1)。
整个函数的正确性依赖于寄存器的保存和恢复,以及栈的正确管理。对于递归函数来说,每次递归调用之前,需要保存当前状态(保存寄存器s0),递归调用后需要恢复它,以便进行下一个递归调用或返回结果。这是因为递归函数每次调用都需要一个独立的栈帧来保存其局部变量和状态。
处理大型数据结构
假设我们想要写一个过程 vadd(a, b, c) 来将两个数组 a 和 b 相加,并将结果存储在数组 c 中。假设数组太大,不能完全存储在寄存器中。
我们将逐个将 a 和 b 的元素搬运到寄存器中,相加后再存储回内存。
由于 vadd 可以用不同的参数被调用,我们需要考虑如何从调用过程将参数传递给 vadd。这需要调用者和被调用者约定如何通过栈传递大型数据结构的信息。
向过程传递数组
- 我们可以将数组分成大小为k的块,这些块足够小,可以适配寄存器,并且可以由vadd过程来添加这两个小块数组。当然,调用者需要调用这个过程n/k次来添加所有元素!
- 更好的方式是将a,b和c的基地址传递给过程,并让它直接访问内存。
- 这与我们迄今为所见的情况有很大不同,因为被调用的过程可以访问其激活帧之外的内存。
过程 vadd(a, b, c) 中,我们需要处理的大型数据结构(如大型数组)的基地址被传递给过程。在这种情况下,过程会根据基地址和元素索引计算出每个元素的确切内存地址,然后使用 lw 指令将这些元素加载到寄存器中,执行必要的算术操作,最后使用 sw 指令将结果写回内存。
这里提到的“将基地址传递给过程”其实就是将数组的起始内存地址传递给过程,这样过程就可以根据这个地址和偏移量来直接访问内存中的每个元素。这是一种间接寻址的方式,它允许过程通过偏移量计算来定位数组的每个元素,而无需将整个数组复制到过程的激活帧中。简单来说,过程得到的是一个指针,指向数组的首个元素所在的内存地址。
例如,如果有一个过程 vadd(a, b, c) 被调用,并且参数 a, b, c 分别是数组 A, B, C 的起始地址,过程可以像下面这样访问数组 A 的第 i 个元素:
# 计算 A[i] 的地址
add t0, a0, t1 # t1 中存储了 i * sizeof(element)
# 加载 A[i] 到寄存器
lw t2, 0(t0) # t2 现在包含了 A[i] 的值
这里 a0 是寄存器,包含了数组 A 的起始地址,而 t1 是另一个寄存器,包含了所需元素的索引乘以该元素类型所占的字节数(偏移量)。过程会用 lw 指令来加载实际的数组元素到另一个寄存器 t2 中,进行运算,然后可能再使用 sw 将结果写回到数组 C 中。这样的操作会在整个数组上循环进行,直到所有元素被处理完毕。
RISC-V内存布局
- 主存中的文本(代码)、静态和堆区域是连续放置的,从低地址开始。
- 堆向更高地址增长。
- 栈从最高地址开始,向更低地址增长。
sp(栈指针)指向栈顶。gp(全局指针)指向静态区域的起始。
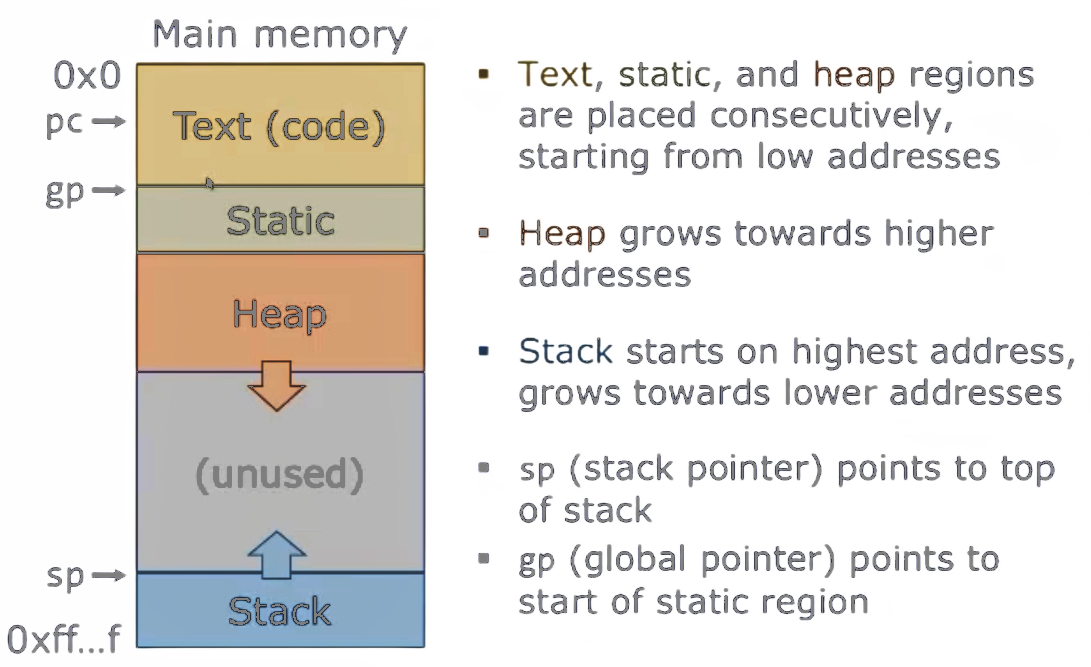
- 大多数编程语言(包括C)有三个独立的内存区域用于数据:
- 栈:存储过程调用使用的数据。
- 静态:持有程序整个生命周期内的全局变量。
- 堆:存储动态分配的数据。
- 在C中,程序员手动管理堆,使用
malloc()分配新数据,并用free()释放。 - 在Python、Java和大多数现代语言中,堆是自动管理的。程序员创建新对象(例如,在Python中的
dict()),但系统只有在安全释放它们(没有指针指向它们时)才会释放它们。
- 在C中,程序员手动管理堆,使用
- 另外,文本区域存储程序代码。
作为参数传递复杂数据结构
- 寻找数组中最大元素的示例函数:
- C 语言代码:
// 在大小为size的数组a中找到最大的元素
int maximum(int a[], int size) {
int max = 0;
for (int i = 0; i < size; i++) {
if (a[i] > max) {
max = a[i];
}
}
return max;
}
int main() {
int ages[5] = {23, 4, 6, 81, 16};
int max = maximum(ages, 5);
}
- RISC-V 汇编语言实现:
maximum:
mv t0, zero // t0: i 初始化为 0
mv t1, zero // t1: max 初始化为 0
j compare // 跳转到比较标签
loop:
slli t2, t0, 2 // t2: i*4,计算数组索引 i 对应的字节偏移量
// t3: addr of a[i],计算 a[i] 的内存地址
add t3, a0, t2
lw t4, 0(t3) // t4: a[i],从内存加载 a[i] 的值
ble t4, t1, endif // 如果 a[i] 小于等于 max,则跳到 endif
mv t1, t4 // max = a[i],更新最大值
endif:
addi t0, t0, 1 // i++
compare:
blt t0, a1, loop // 如果 i < size,则继续循环
mv a0, t1 // a0 = max,将最大值移到返回值寄存器
ret // 返回到调用者
在汇编代码中,程序首先初始化循环变量 i(寄存器 t0)和最大值变量 max(寄存器 t1)为0。然后,进入主循环之前,执行比较来判断是否继续循环。循环体中使用左移操作(slli)和加法来计算数组元素的内存地址,加载元素值(lw),比较当前元素值是否大于已知的最大值,如果大于,更新最大值。循环后,如果索引小于数组大小,程序将回到循环的开始。循环结束后,将找到的最大值放入 a0 寄存器,这是 RISC-V 中用于返回函数结果的寄存器,并返回到调用者。
主函数 main 初始化一个名为 ages 的数组并调用 maximum 函数来找到数组中的最大值并存储在变量 max 中。在汇编中,数组 ages 的基地址通过寄存器 a0 传递给 maximum 函数,而数组的大小则通过寄存器 a1 传递。这样,maximum 函数就可以直接访问和操作内存中的数组元素。
为什么不总是使用指针作为参数?
// 计算三角形的周长
int perimA(int a, int b, int c) {
int res = a + b + c;
return res;
}
// 计算多边形的周长
int perimB(int sides[], int size) {
int res = 0;
for (int i = 0; i < size; i++) {
res += sides[i];
}
return res;
}
间接寻址可以是昂贵的:
- 需要额外的内存引用。
- 执行速度可能较慢。
传递复杂数据结构作为参数或返回值
- 其他复杂的数据结构,比如字典、结构体、链表等,将遵循同样的方法,即通过指针将数据结构作为参数传递给过程,同时提供所需的其他信息,如元素数量等。
- 类似地,当返回值是一个复杂的数据结构时,该数据结构存储在内存中,过程返回一个指向该数据结构的指针。
Take home
- 讨论如果一个过程需要10个参数(即,参数数量多于寄存器可以存放的数量),应该如何实现。
在解释如何处理超过寄存器能存储的参数数量的过程时,如果一个过程需要的参数超出了可用的参数寄存器数目,那么这些参数需要通过栈来传递。调用者会在调用过程之前,把超出寄存器数量的参数推入栈中。被调用过程(callee)则可以通过访问栈来读取这些参数值。
如何在汇编中处理输入和输出?
- 内存映射I/O(Memory Mapped I/O)
- 使用相同的地址空间来映射内存和I/O设备。
- I/O设备监控CPU内存请求并对使用I/O设备关联地址的内存请求做出响应。
- MMIO地址只能用于I/O,不能用于常规存储。
MMIO地址
- 输出(Outputs):
0x4000 0000- 执行sw到这个地址会在控制台打印一个ASCII字符,对应于此地址存储的值的ASCII等价值。0x4000 0004- 执行sw到这个地址会打印一个十进制数字。0x4000 0008- 执行sw到这个地址会打印一个十六进制数字。
- 输入(Inputs):
0x4000 4000- 执行lw从这个地址会从控制台读取一个有符号字。- 重复执行
lw到这个地址会读取下一个输入字等等。
内存映射I/O是一种机制,允许CPU通过读写特定的内存地址来与外设进行数据交换,而不需要特殊的I/O指令。输出地址映射到外设,用于发送数据,而输入地址用于接收数据。这种方式使得I/O操作对于程序来说就像访问内存一样简单。
在RISC-V汇编中,这意味着可以使用普通的内存访问指令(如 lw 和 sw)与硬件设备进行通信,而这些设备会响应这些特定地址上的读写操作。
内存映射I/O示例 1
// 加载读取端口到t0
li t0, 0x40004000
// 读取第一个输入
lw a0, 0(t0)
// 读取第二个输入
lw a1, 0(t0)
// 把它们相加
add a0, a0, a1
// 加载写入端口到t0
li t0, 0x40000004
// 写出结果
sw a0, 0(t0)
内存映射I/O示例 2
// 准备从控制台读取输入
li t0, 0x40004000
// 获取用户输入
lw a0, 0(t0)
// 再次获取用户输入
lw a1, 0(t0)
// 启动性能计数器,将1存储到特定地址
li t1, 0x40006000
sw t2, 0(t1)
// 把输入相加
add a0, a0, a1
// 停止性能计数器,将0存储到特定地址
sw zero, 0(t1)
// 准备将结果打印为十进制数
li t0, 0x40000004
// 打印和
sw a0, 0(t0)
// 从性能计数器获取计数
lw t2, 0(t1)
// 打印计数
sw t2, 0(t0)
MMIO用于性能度量
-
性能度量:
-
0x4000 5000:执行加载指令(lw)从该地址可以获取从程序执行开始的指令计数。 -
0x4000 6000:执行加载指令(lw)从该地址可以获取打开和关闭性能计数器之间的指令数量。 -
0x4000 6004:- 执行存储指令(
sw)并向该地址写入0,可以关闭性能计数器。 - 执行存储指令(
sw)并向该地址写入1,可以打开性能计数器。
- 执行存储指令(
-
在示例1中,MMIO被用于从I/O端口读取数据并将数据写入I/O端口。在示例2中,除了读取和写入外,还展示了如何使用MMIO地址监控程序的性能,例如计算指令数量。这两个例子都展示了MMIO如何让汇编程序能够与硬件I/O设备进行交互,这对于嵌入式系统和操作系统级别的编程非常关键。
回顾
- 程序和调用约定:
- 程序通常需要通过调用函数来执行复杂的任务,这些调用遵循特定的规则集,即调用约定。
- 调用约定定义了如何在寄存器中传递参数,哪些寄存器需要保存(caller-saved)和恢复(callee-saved),以及栈的使用方式。
- 当函数需要的参数数量超过寄存器能够容纳的数量时,额外的参数通常通过栈传递。
- 递归和嵌套函数调用:
- 递归函数是自己调用自己的特殊函数,它们是嵌套函数调用的一个例子。
- 在嵌套或递归调用中,保持调用链的完整性至关重要,这通常涉及到在栈上管理激活记录(activation records),确保每次函数调用都有其自己的状态空间。
- 内存映射I/O(MMIO):
- MMIO是一种将设备寄存器映射到内存地址空间的技术,使得程序可以通过标准的内存访问指令来读取和写入这些设备寄存器。
- MMIO使程序能够通过使用
lw(load word)和sw(store word)指令与I/O设备交互。
- MMIO的性能度量应用:
- 特定的MMIO地址可以用来访问性能计数器,例如指令计数器,这可以帮助监控和优化程序性能。
- 通过写入特定的MMIO地址,程序可以开启或关闭性能计数器,获取执行指令的数量等信息。
- MMIO示例:
- 在给出的示例中,展示了如何使用MMIO读取控制台输入和输出到控制台,以及如何使用MMIO地址进行性能监控。
总体来说,这些概念为理解程序在低级别如何运行提供了重要的基础,特别是在涉及函数调用的上下文中如何正确地传递参数、管理栈、以及与外部设备进行通信。MMIO的使用是嵌入式系统和驱动程序开发中特别常见的,它使得软件能够直接与硬件交互。