开始 - 介绍与资源
在这个系列中,我们将共同学习三门课程(MIT 6.004, MIT 6.175, MIT 6.375)。大部分的内容都是基于 ChatGPT 对相关资源的翻译和解释,以及本站作者的审核调整和补充,希望能帮助大家更好地理解这些复杂的概念。
MIT的这三门课程涵盖了计算机科学和电子工程的一些高级主题。下面是每门课程的详细介绍:
MIT 6.004:计算系统结构(Computation Structures)
MIT 6.004 主要教授计算机系统的基本构造块。学生将学习有关硬件和软件接口的知识,包括处理器设计、存储器层次结构和异步序列器。此课程涉及如何从低级硬件构建出能够运行软件应用的系统。此外,学生也会学到如何使用模拟工具和硬件描述语言来设计和测试这些系统。
MIT 6.175:构造可靠的数字系统(Constructive Computer Architecture)
MIT 6.175 课程着重于数字系统的构造,特别是在处理器设计领域。学生会学习到如何设计、构建和测试处理器和微处理器。课程内容包括数字逻辑、微架构、流水线和优化以及测试和验证技术。此外,该课程还会使用现代的硬件描述语言和验证工具,教授如何构建高性能且可靠的计算机硬件。
MIT 6.375:设计和实施数字系统(Design and Implementation of Digital Systems)
MIT 6.375 专注于数字系统的设计和实施,尤其是通过使用现场可编程门阵列(FPGA)。课程内容涵盖了从理论到实践的所有方面,包括硬件描述语言、系统设计、性能分析和优化以及FPGA的特定技术。此课程特别适合对硬件设计感兴趣的学生,并且强调实际操作和实验。
这些课程都非常适合对计算机硬件和系统设计感兴趣的学生,尤其是那些希望在未来从事硬件工程或系统架构设计的学生。每门课程都有丰富的实验和项目,帮助学生将理论知识转化为实践能力。
随着课程内容的深入,我们将探讨更多高级主题,包括但不限于集成电路的设计、优化和测试。无论你是计算机科学的新手还是经验丰富的工程师,这个系列都将是一个宝贵的资源,帮助你在计算机科学和工程领域取得进步。
在追求深入了解的过程中,我们还强调提高个人的动手实践能力。为了做到这一点,我们鼓励学生自行搜集和利用开源资料,掌握实际操作和实验。我们坚信通过亲自动手实践和主动搜寻资料,学生能够更好地巩固理论知识,并在计算机科学领域和开源社区取得更大的进步。
敬请期待后续的更新,我们将继续深入这些激动人心的课程,解锁计算机科学的更多秘密!
![]()

注意!ChatGPT 可能会出错,考虑检查重要信息,尤其是数学逻辑相关内容 ChatGPT 会产生大量幻觉,本站作者已经尽力审核调整和补充。不过同样,本站作者的调整和补充可能并不准确。具体内容以课程表述为准,本站只做参考理解使用。如果发现任何问题,请在...反馈。
MIT公开课内容介绍
下面内容来自计算机体系结构 l MIT课程学习新手上路宣讲 - 达坦科技 米明恒
我们选择了MIT的3门公开课程作为学习资料:
- MIT 6.004
- 本科课程水平,优点是配有视频教材,适合初次接触。通过这些视频,学生可以系统地理解和掌握相关知识。
- MIT 6.175
- 硕士课程水平,优点是拥有详细的课件和实验资料,有非常完善的Lab和Project。我们主要以此为基础,也会参考并建议学习MIT 6.004的视频内容,以弥补6.004的实验缺陷。
- MIT 6.375
- 精讲精练的选修课,课程时间比较短,强调了编程语言Bluespec SV(Bluespec System Verilog, BSV)语言的使用,课程提供了4+1 Lab。由于这门课程的内容与6.175有重合,我们建议在完成6.175的学习后再学习。
-
Bluespec介绍与特点:
- Bluespec是一门现代的硬件描述语言,由MIT的Arvind教授主导开发。易于使用且强调安全性,但其社区和生态较小,资源和用户较少。
-
三门公开课中Bluespec的作用和位置:
- Bluespec与Chisel, SpinalHDL等HDL一样,都是用于硬件开发的现代工具,优于传统的Verilog设计方式。Bluespec提供了更抽象的语言特性,有助于提高开发效率,但需要时间学习并掌握。
-
6.004课程内容简介:
- 6.004包含了一系列的视频讲座,覆盖了RISC-V处理器及其汇编语言,编译技术和操作系统等核心计算机科学领域知识,并结合实验(如硬件机构原理)进行讲解。提供了一个视频选集链接(Bilibili 6.004课程视频),方便直接访问。
6.004
6.004课程内容涵盖从计算机系统的基础概念、组合逻辑电路、到寄存器文件和存储系统的设计等。它强调理解和掌握基础知识,并通过实验学习BlueSpec语言进行硬件设计,使学生能够在实践中找到理论与实用之间的平衡。(Bilibili 6.004课程视频)
第1部分:L01 - L04
- L01 - 引言 (Introduction)
- L02 - RISC-V 汇编 (RISC-V Assembly)
- L03 - 编译代码、过程及栈 (Compiling Code, Procedures, and Stacks)
- L04 - 过程和存储映射I/O (Procedures and MMIO)
一些概述性质的课程,分别介绍了RISC-V处理器及其汇编语言、软件的编译过程、函数调用栈之类的基础知识,相当于在复习国内《计算机组成原理》这门课程。
第2部分:L05 - L10
- L05 - 组合逻辑 (Combinational Logic)
- L06 - Barrel Shifter 和 Boolean 优化 (Barrel Shifter, Boolean Optimizations, and Logic Synthesis)
- L07 - 在Bluespec中的复杂组合电路 (Complex Combinational Circuits in Bluespec)
- L08 - 算术电路设计权衡 (Design Tradeoffs in Arithmetic Circuits)
- L09 - 时序电路 (Sequential Circuits)
- L10 - 时序电路:带有保护接口的模块 (Sequential Circuits, Modules with Guarded Interfaces)
相当于在带领大家复习《数字电路》课程相关知识,在这里会开始穿插着介绍Bluespec的一些基础语法知识。在这里可以学会BSV中如何描述组合逻辑、时序逻辑,以及电路设计中的一些trade-off。
第3部分:L11 - L12
- L11 - 在Bluespec中的硬件综合 (Hardware Synthesis in Bluespec)
- L12 - 模块接口与并发性 (Module Interfaces and Concurrency)
重点!这里将涉及到两个重要知识点:
-
BSV程序的各个模块之间是怎样握手的(不同于Verilog需要开发者自己去处理模块间的握手,BSV将模块间的握手抽象成了和软件函数调用一样简单的写法,这意味着BSV编译器会在背后做很多工作,你需要了解BSV编译器自动生成了什么样的握手信号)
-
BSV中Conflict Matrix的概念,理解了这个概念,你才能知道BSV是如何并行调度执行你所写的代码的。
第4部分:L13 - L23
- L13 - 在硬件中实现RISC-V处理器 (Implementing RISC-V Processor in Hardware)
- L14 - 多周期处理器 (Multicycle Processors)
- L15 - 存储层次结构 (The Memory Hierarchy)
- L16 - 存储系统设计与实现 (Memory Systems: Design and Implementation)
- L17 - 操作系统 (Operating Systems)
- L18 - 虚拟内存 (Virtual Memory)
- L19 - 流水线引言 (Introduction to Pipelining)
- L20 - 处理器流水线 (Processor Pipelining)
- L21 - 实现流水线 (Implementing Pipelines)
- L22 - 同步 (Synchronization)
- L23 - 实现处理器流水线 (Implementing Processor Pipelines)
这一部分开始教大家如何用BSV编写RISC-V处理器,从最初的单周期一直到多级流水线。其中会继续穿插着介绍BSV语言本身的特性,以及存储器、操作系统、虚拟内存等相关的知识。
第5部分:L24 - L25
- L24 - 数字抽象和时序约束 (The Digital Abstraction and Sequential Timing Constraints)
- L25 - 缓存一致性 (Cache Coherence)
介绍了时序约束和缓存一致性相关的内容
6.175
6.175课程内容简介 ( http://csg.csail.mit.edu/6.175/index.html )
由于6.175没有视频课程,但是它的课件非常完善,除了课件以外还有Textbook,因此6.175非常适合配合着6.004的视频一起同步学习。
6.175的实验也建议配合着6.004的视频同步开展。
相比于6.004,6.175的课程在Conflict Matrix、处理器流水线、缓存一致性的介绍上会更加深入。
6.175的课件有PPT和PDF两个版本,PPT版本有动画效果,强烈建议看PPT版本。
在实验上,由于6.175的课程开设了很多年,前些年采用的是MIPS处理器来讲的,最近换成了RISC-V处理器,所以有些资料可能是MIPS的,但是不影响大家学习。不过做实验的时候要找好代码框架,不要做成MIPS版本的实验。
6.175的实验室内容由3个大部分:
-
Lab0~Lab4,熟悉Bluespec语言和处理器基础知识,其中:
- Lab0~Lab3:主要是熟悉Bluespec的语法,如何编写仿真和验证、时序验证、流水线设计等。
- Lab4 在重点训练 Conflict Matrix,很重要,一定要认真做明白。
-
Lab5~Lab8,RISC-V处理器实验,通过过一步步的迭代,达到性能优化和增加新的功能。
-
Project1~Project2,涉及到多核处理器以及多核之间的缓存一致性。
注意,6.175课程网站具有不同年份的存档,目前主页默认是2017年的课程安排,但在实验方面,2017年的实验难度低于2016年的实验(主要体现在Project部分),因此建议大家在做实验的时候,选择2016年的课程网站进行学习。另外,不同年份的PPT、助教答疑PPT等内容也有一些区别,有精力的同学可以把两年的都看一下。
6.375
6.375课程内容简介 ( http://csg.csail.mit.edu/6.375/6_375_2019_www/index.html )
- 6.375 实验指导书写的很长,会在实验指导书里教给大家关于BSV的一些高级用法。相比课件更推荐实验指导书。
- 6.375 也有一份Textbook,这个Textbook是6.175的Textbook的前半部分的高消重制版,对于数电基础知识,以及Bluespec的Confict Matrix、调度算法等有更详细的介绍。如果6.175的Textbook还没有满足你的好奇心,或者感觉6.175的Textbook讲的不清楚,那么可以试试阅读6.375的Textbook,但是6.375的Textbook没有涉及到处理器相关的部分。
- 6.375 的实验内容侧重于信号处理以及BSV的高级语法,同时也涉及到软硬件联合开发调试的一些内容。
- 6.375 的课件还讲了很多BSV的其他应用案例,但是6.375的实验却没有涉及到这些部分。所以6.375的课件大家有选择的看就行了,有精力的可以把所有课件都看了。理论上看为6.004和6.175之后,6.375的课件应该看起来比较简单了。
实验的学习顺序
- 6.175 Lab0~Lab4
- 熟悉BSV基础语法,Conflict Matrix
- 6.375 Lab1~Lab4
- 强化BSV语法,熟悉软硬件联合调试框架Connectal,为后续处理器实验做准备
- 6.175 Lab5~Lab8
- 编写RISC-V处理器
- 6.175 Proj1~Proj2
- 实现Store Queue和多核缓存一致性
- 6.375 Lab5(选做)
- 前置6.175的Project以后,这个实验相对较为简单
推荐的学习顺序
- MIT6.004 L01 - L04
基础知识,不对应具体的Lab,但是对做Lab有帮助,帮助大家了解软件和硬件的交互边界
- MIT6.004 L04 - L08
对应6.175 Lab0-Lab3
- MIT6.004 L08 - L12
对应6.175 Lab3-Lab4,以及6.375的Lab1-Lab4
- MIT6.004 L13 - L24
对应6.175 Lab5-Lab8
- MIT6.004 L22 - L25
对应6.175 Project 1-2
学习资料
Bilibili 6.004课程视频
6.175 课程官网
- Schedule
- 课件
- Resources
- 切换2016版本
- Textbook
- Labs
- 实验指导书
6.375 课程官网
另:
- BSV资源
- 标准库文档
- BSV编译器说明
- Bluespec文档
- 6.175实验环境在GitHub早年仓库寻找
实验环境搭建
BSV工具链
实验环境的代码问题解决了以后,下一步是实验环境工具链的搭建,这里同样不直接给出具体的操作指南,仅给出一些可选的方案,具体选择哪一种,都有各自对应的坑需要大家自己去踩。毕竟搭建环境也是能力考察的 一部分。
方案1:纯手工搭建
- BSV的编译器可以到GitHub上BSV的官网release页面直接下载,WangXuan同学的中文教程里有步骤,不是很难
- 6.375的Lab4和6.175的后几个Lab会用到一个叫Connectal的开发框架,这个框架安装比较折腾人
方案2:使用Docker开发环境
- 可以搜索connectal-docker这个开源镜像,是我们之前的一位实习同学自己搭建的,集成了BSV编译器和Connectal
- 需要大家对docker比较熟悉
Connecta是什么?
Connectal是剑桥开发的一个软硬件联合调试的框架,可以方便的在FPGA和PC之间打通一个数据交换的通道。在近几年RISC-V相关的Lab中,使用Connectal搭建了测试框架用于监测自己编写的RISC-V处理器的工作状态。
RISC-V工具链
下面是RISC-V工具链相关的东西,Lab5~Lab8及Project 1~2需要用到。
因为后面要自己编写RISC-V处理器,并且在RISC-V处理器上运行测试用的汇编程序和C程序,所以需要自己动手安装RISC-V的编译工具链。
存在的坑:
-
实验环境代码用到的编译器版本比较古老,新的RISC-V GCC编译器的一些命令行参数已经发生了改变,需要大家自己去调整。
-
GCC编译得到的可执行文件需要通过一定的方式传给仿真器里面跑的RISC-V处理器使用,这里也有不同的工具可以使用,而这些工具可能也存在版本问题,不同版本转换出来的二进制文件格式不一样,需要大家自己修改。
-
关于把可执行文件喂给仿真器这件事,不同年代的实验代码也有不同的实现方式,有的是通过把ELF文件格式转换成BIN或者VMH格式的文件让仿真器读取,有的是通过Connectal作为通道直接使用ELF文件,各有利整,大家可以自行对比不同版本的实验代码。
实验对应环境需求
只需要BSV编译器,没必要一开始就配置Connectal和RISC-V工具链
- 6.175 Lab0-4
- 6.375 Lab1-3
需要BSV编译器和Connectal
- 6.375 Lab4
- 6.175 Lab5
需要BSV编译器、Connectal以及RISC-V工具链
- 6.175 Lab5-8 Proj1-2
FAQ
- 有一些实验需要用用到FPGA开发板,这部分涉及到上板实验的部分先跳过即可,我们只做软件仿真部分。
- 作为开源项目的参与者,必须自己有很强的Debug能力,要习惯于自己踩坑。所以本次新手入门,有一些坑并没有展示给大家,就是留着让大家去踩的。
- 没有太多中文资料,做开源,与全球的开发者交流,基本的英语读写能力还是需要的。和GitHub或者其他资料网站打不开怎么办--自己修炼魔法,这也是必备技能。
- 6.175的Lab2和Lab3可能网页上的顺序和GitHub找到的代码顺序是颠倒的。如果你遇到了这个情况,那就先做Lab3再做Lab2。正确的顺序就是先加法器,再乘法器,再FFT。
- 6.375的Lab是以信号处理为主题的,但是大家不用关注信号处理算法本身,而是重点关注Bluespec本身的一些高级语法。
- 建议大家在做实验的时候阅读TestBench的代码,而不是只写实验代码,事实上,有一些Debug工作需要你在了解了TestBench是如何工作以后才能找到问题,甚至有的TestBench本身就有问题。
- 关于查看仿真波形这件事,整套实验的指导书里面都没有教大家如何查看波形,我们也不是特别鼓励大家去看波形。看波形并不是一个高效的debug手段,也难以做到自动化评测。我们建议大家更多的了解BSV自带的仿真器bluesim的特性,采用更高效的手段来debug,将更多软件开发中的debug方式应用到硬件开发中。当然,如果你对看波形有执念,bluesim也可以导出vcd格式的波形文件,大家可以自己学习。
- 如果感觉入门还是比较费力,可以考虑先自学一生一芯项目的基础课程,然后再挑战MIT的实验课程。
- 关于何时提交代码:如果只是对BSV感兴趣,想学习BSV语言的同学,大家直接在群里互相交流即可,但是对于有申请达坦实习岗位的同学,BSV的学习是面试流程的一部分,需要在完成6.175的Lab0~Lab2之后主动联系达坦科技的同学对大家的代码进行Review。(达坦科技实习相关)
- 如果是申请实习的同学,建议在1~2个月内完成所有实验。
- 达坦科技DatenLord官网
- B站:达坦科技DatenLord
- GitHub
附:MIT 6.004课程内容目录
课程链接:MIT 6.004公开课程
-
L01 - 引言 (Introduction)
-
L02 - RISC-V 汇编 (RISC-V Assembly)
-
L03 - 编译代码、过程及栈 (Compiling Code, Procedures, and Stacks)
-
L04 - 过程和存储映射I/O (Procedures and MMIO)
-
L05 - 组合逻辑 (Combinational Logic)
-
L06 - Barrel Shifter 和 Boolean 优化 (Barrel Shifter, Boolean Optimizations, and Logic Synthesis)
-
L07 - 在Bluespec中的复杂组合电路 (Complex Combinational Circuits in Bluespec)
-
L08 - 算术电路设计权衡 (Design Tradeoffs in Arithmetic Circuits)
-
L09 - 时序电路 (Sequential Circuits)
-
L10 - 时序电路:带有保护接口的模块 (Sequential Circuits, Modules with Guarded Interfaces)
-
L11 - 在Bluespec中的硬件综合 (Hardware Synthesis in Bluespec)
-
L12 - 模块接口与并发性 (Module Interfaces and Concurrency)
-
L13 - 在硬件中实现RISC-V处理器 (Implementing RISC-V Processor in Hardware)
-
L14 - 多周期处理器 (Multicycle Processors)
-
L15 - 存储层次结构 (The Memory Hierarchy)
-
L16 - 存储系统设计与实现 (Memory Systems: Design and Implementation)
-
L17 - 操作系统 (Operating Systems)
-
L18 - 虚拟内存 (Virtual Memory)
-
L19 - 流水线引言 (Introduction to Pipelining)
-
L20 - 处理器流水线 (Processor Pipelining)
-
L21 - 实现流水线 (Implementing Pipelines)
-
L22 - 同步 (Synchronization)
-
L23 - 实现处理器流水线 (Implementing Processor Pipelines)
-
L24 - 数字抽象和时序约束 (The Digital Abstraction and Sequential Timing Constraints)
-
L25 - 缓存一致性 (Cache Coherence)
MIT 6.004 Computation Structures
课程目录
课程链接:MIT 6.004公开课程
-
L01 - 引言 (Introduction)
-
L02 - RISC-V 汇编 (RISC-V Assembly)
-
L03 - 编译代码、过程及栈 (Compiling Code, Procedures, and Stacks)
-
L04 - 过程和存储映射I/O (Procedures and MMIO)
-
L05 - 组合逻辑 (Combinational Logic)
-
L06 - Barrel Shifter 和 Boolean 优化 (Barrel Shifter, Boolean Optimizations, and Logic Synthesis)
-
L07 - 在Bluespec中的复杂组合电路 (Complex Combinational Circuits in Bluespec)
-
L08 - 算术电路设计权衡 (Design Tradeoffs in Arithmetic Circuits)
-
L09 - 时序电路 (Sequential Circuits)
-
L10 - 时序电路:带有保护接口的模块 (Sequential Circuits, Modules with Guarded Interfaces)
-
L11 - 在Bluespec中的硬件综合 (Hardware Synthesis in Bluespec)
-
L12 - 模块接口与并发性 (Module Interfaces and Concurrency)
-
L13 - 在硬件中实现RISC-V处理器 (Implementing RISC-V Processor in Hardware)
-
L14 - 多周期处理器 (Multicycle Processors)
-
L15 - 存储层次结构 (The Memory Hierarchy)
-
L16 - 存储系统设计与实现 (Memory Systems: Design and Implementation)
-
L17 - 操作系统 (Operating Systems)
-
L18 - 虚拟内存 (Virtual Memory)
-
L19 - 流水线引言 (Introduction to Pipelining)
-
L20 - 处理器流水线 (Processor Pipelining)
-
L21 - 实现流水线 (Implementing Pipelines)
-
L22 - 同步 (Synchronization)
-
L23 - 实现处理器流水线 (Implementing Processor Pipelines)
-
L24 - 数字抽象和时序约束 (The Digital Abstraction and Sequential Timing Constraints)
-
L25 - 缓存一致性 (Cache Coherence)
课程信息
- 课程名称:Computation Structures
- 开课学期:Spring 2019
- 教师团队:包括Arvind, Silvina Hanono Wachman, Jason Miller等,以及多名助教。
课程简介
MIT的6.004课程探讨了计算机系统的基本构建块,专注于通用处理器的设计。课程内容涵盖了从数字逻辑到操作系统等方面的知识,旨在培养学生理解和设计RISC-V处理器的能力。
课程内容概述
计算设备的演变
- 从1943年的ENIAC到2018年的典型笔记本电脑,计算设备经历了巨大的变化,体现在体积、功耗和计算能力上的巨大差异。
通用处理器设计
- 微处理器是计算机系统的基本构建块。
- 学习微处理器的设计对于理解硬件极为重要。
- 课程目标是让学生能够从零开始设计多个RISC-V处理器。
课程重点
- 模块一:介绍二进制表示和操作,RISC-V指令集架构,汇编语言编程等。
- 模块二:讲解数字抽象,布尔代数与组合逻辑,时序逻辑,以及逻辑设计的Bluespec表达。
- 模块三:实现非流水线和流水线RISC-V计算机,包括缓存,控制和数据危害处理,分支预测等。
- 模块四:操作系统概念,I/O中断与异常,虚拟内存。
- 模块五:并行编程,多核问题,同步,缓存一致性等高级主题。
设计与实验
- 课程强调使用现代设计工具,如Bluespec SystemVerilog(BSV)和Yosys合成工具,进行处理器设计和实验。
- 学生将完成多个设计任务,包括不同阶段的RISC-V处理器设计。
课程安排
- 包括每周两次讲座和两次辅导课。
- 八个实验和一个终期设计项目。
- 三次测验。
资源与支持
- 课程网站提供最新信息、讲义和补充阅读材料。
- Piazza论坛用于课程公告和答疑。
评分与要求
- 实验、设计项目和测验构成了主要的评分部分。
- 要求学生积极参与课堂和辅导课。
反馈与互动
- 课程强调学生反馈的重要性,鼓励学生通过电子邮件或Piazza分享意见。
L01 Introduction
MIT 6.004 Spring 2019 课程的开篇讲座,由教授Arvind主讲。
课程旨在通过实际构建计算机的过程,深入理解计算机的内部工作原理。Arvind教授强调,了解通用处理器的设计对于深入理解硬件极其重要,即使学生未来不从事硬件设计工作。本课程将围绕设计多个RISC-V处理器进行。
课程内容概览
-
技术发展历程:从1943年的ENIAC到现代笔记本电脑的技术演进,展示了计算设备的惊人进步。
-
通用处理器的重要性:无论硬件大小,通用处理器的设计原理相同。理解这些原理有助于设计各种硬件。
-
课程目标:课程的主要目标是通过实际构建不同内部设计的RISC-V处理器,理解计算机的运行原理。
-
程序和硬件的关系:介绍了高级编程语言、汇编语言和硬件之间的关系,强调了了解这一接口对于硬件设计的重要性。
-
数字计算的基本原理:所有现代电子计算机都是数字的,以二进制形式进行计算。了解这些基本操作对于硬件设计至关重要。
-
课程模块:
- 二进制表示、RISC-V ISA、汇编语言编程等基础。
- 数字抽象、布尔代数、组合逻辑、时序逻辑和硬件设计语言Bluespec。
- 实现非流水线和流水线RISC-V计算机、缓存、分支预测等高级主题。
- 操作系统、I/O中断、异常和虚拟内存。
- 并行编程、多核问题、同步、缓存一致性等并行计算主题。
-
设计工具:课程中使用Bluespec SystemVerilog和Yosys合成工具,从高级描述自动生成电路。
课程实践
- 学生将完成8个实验和一个开放性设计项目,使用Bluespec进行处理器设计。课程通过实验、设计项目和测验进行评分。
MIT 6.004 2019年春季课程的大纲:
- 模块 1:RISC-V汇编语言编程(4讲)。
- 模块 2:数字逻辑设计(8讲),内容涵盖布尔代数、组合电路、时序电路、在Bluespec中表达逻辑设计、逻辑综合(包括将Bluespec设计转化为逻辑电路,以及将逻辑电路转化为标准的门电路库),以及并发问题。
- 模块 3:RISC-V处理器(6+1讲)。
- 模块 4:操作系统、输入/输出、虚拟内存(3讲)。
- 模块 5:多核处理器(2讲)。
L02 RISC-V haskell and Binary Notation
MIT 6.004 Spring 2019 L02 RISC-V haskell,由Silvina Hanono Wachman讲述。
主要内容包括RISC-V汇编语言的继续讨论和二进制表示的深入探讨。
RISC-V汇编语言讨论
- 介绍了RISC-V指令集架构(ISA),这是软件和硬件之间的一种契约,规定了处理器可以进行的所有操作、可用的存储空间以及如何利用这些硬件资源。
- 讨论了存储结构,包括32位宽的寄存器文件和主存储器,以及用于访问常数和内存中数据的指令格式。
- 详细说明了如何执行计算指令、控制流指令(条件分支和无条件跳转)以及如何进行加载和存储操作,包括使用基址加偏移量的方法来访问内存。
指令和操作
- 通过示例详细讲解了RISC-V汇编语言中包括算术运算、逻辑运算、移位操作、加载和存储数据、以及如何实现条件分支和跳转等指令的使用。
- 强调了汇编语言中使用的二进制和十六进制表示法,以及如何将高级语言中的表达式和控制流结构翻译成汇编指令。
课程结束部分
- 课程的最后部分讨论了使用二进制表示负数的方法,即二进制补码表示法,并指出所有汇编指令中使用的常数都采用二进制补码形式。
- 虽然时间有限,未能覆盖所有内容,但计划在下次课堂讨论中继续深入讲解。
分页知识点
微处理器的组件
- 寄存器文件(Register File):存储临时数据,可以快速访问。
- 算术逻辑单元(ALU):执行算术和逻辑操作。
- 主内存(Main Memory):存储程序和数据,由地址和数据组成,每个内存位置是 32 位宽。
RISC-V 处理器存储
- 主内存中的每个位置是 32 位宽(4 字节)。
- 寄存器:32 个通用寄存器,每个寄存器是 32 位宽。
- x0 寄存器:硬编码为 0,任何写入 x0 的操作都不会改变其值。
RISC-V 指令集架构(ISA)
- ISA 的定义:软件和硬件之间的契约,定义操作和存储位置的功能描述。
- RISC-V ISA:一种来自伯克利的新开放 ISA,包括不同的数据宽度和指令。
- 指令类型:
- 计算指令:在寄存器上执行算术和逻辑操作。
- 加载和存储指令:在寄存器和主内存之间移动数据。
- 控制流指令:更改指令执行顺序,支持条件语句和循环。
计算指令
-
算术、比较、逻辑和移位操作:
-
寄存器-寄存器指令
:使用两个源操作数寄存器和一个目标寄存器。
- 算术操作:加法(
add)、减法(sub) - 比较:设置小于(
slt)、设置小于无符号(sltu) - 逻辑:与(
and)、或(or)、异或(xor) - 移位:逻辑左移(
sll)、逻辑右移(srl)、算术右移(sra)
- 算术操作:加法(
-
例子:
add x3, x1, x2表示 x3 = x1 + x2。slt x3, x1, x2表示如果 x1 < x2 则 x3 = 1,否则 x3 = 0。and x3, x1, x2表示 x3 = x1 & x2。sll x3, x1, x2表示 x3 = x1 << x2。
二进制运算
- 所有值都是二进制:
- 例如:x1 = 00101; x2 = 00011
add x3, x1, x2表示 x3 = x1 + x2。与十进制中的 5 + 3 = 8 相对应,二进制计算结果为 01000。sll x3, x1, x2表示将 x1 向左移动 x2 位,结果为 01000。
二进制模运算
- 如果我们使用固定数量的位进行计算,加法和其他操作可能会产生超出范围的结果。这称为溢出。
- 通常的做法是忽略额外的位,采用模运算。对于 N 位数字,等同于执行
mod 2^N。 - 视觉上,可以看到数值在最大和最小值之间“环绕”。
十六进制表示法
- 长二进制串手工转换容易出错,因此常用高基数(radix)表示法,十六进制是一种流行的选择。
- 十六进制使用基数16,每4个相邻的二进制位编码为一个十六进制数字。
- 示例:二进制串 011110100000 转换为十六进制为 0x7D0。
寄存器-立即数指令
- 一种操作数来自寄存器,另一个是编码在指令中的小常数。
- 格式:操作 目标寄存器,源寄存器1,常数
addi x3, x1, 3// x3 = x1 + 3andi x3, x1, 3// x3 = x1 & 3slli x3, x1, 3// x3 = x1 << 3
- 注意没有subi指令,而是使用负数常量。
addi x3, x1, -3// x3 = x1 - 3
- 格式:操作 目标寄存器,源寄存器1,常数
控制流指令
- 根据条件执行不同的操作:
- 如果 a < b,则 c = a + 1
- 否则,c = b + 2
- 需要条件分支指令:
- 格式:条件 源寄存器1 比较 源寄存器2,标签
- 如果比较结果为True,则跳转到标签处执行,否则按顺序执行程序。
复合计算
- 执行 a = ((b+3) >> c) - 1;
- 将复杂表达式分解为基本计算。我们的指令只能指定两个源操作数和一个目标操作数(也称为三地址指令)。
- 假设 a, b, c 存在寄存器 x1, x2, 和 x3 中,分别使用 x4 作为 t0, x5 作为 t1。
t0 = b + 3;t1 = t0 >> c;a = t1 - 1;
无条件控制指令:跳转
-
jal:无条件跳转并链接- 例子:
jal x3, label - 跳转目标指定为标签,标签被编码为当前指令的偏移量
- 链接(在下次讲座中讨论):存储在 x3 中
- 例子:
-
jalr:通过寄存器和链接进行无条件跳转- 例子:
jalr x3, 4(x1) - 跳转目标指定为寄存器值加上常数偏移量
- 例子:跳转目标 = x1 + 4
- 可以跳转到任何 32 位地址 - 支持长跳转
- 例子:
以上解释中,“无条件跳转并链接”(jal)是一种跳转指令,用于无条件地将程序的执行流跳转到指定的地址,并将下一条指令的地址保存在寄存器中,通常用于函数调用。 “通过寄存器和链接进行无条件跳转”(jalr)是一种变体,允许跳转到一个基于寄存器值和常数偏移量计算的地址。这些都是 RISC-V 指令集中控制程序流的基础操作。
在内存中执行计算
当我们需要对存储在内存中的值执行计算时,我们会用到加载(load)和存储(store)指令。以计算 a = b + c 为例,我们会按以下步骤进行:
- 从内存地址 Mem[b] 加载 b 的值到寄存器 x1。
- 从内存地址 Mem[c] 加载 c 的值到寄存器 x2。
- 将寄存器 x1 和 x2 中的值相加,并将结果存储到寄存器 x3。
- 将寄存器 x3 的值存储回内存地址 Mem[a]。
例如,如果 b 和 c 分别位于内存地址 0x4 和 0x8,而我们想要将它们的和存储在地址 0x10,对应的汇编代码如下:
lw x1, 0x4(x0)
lw x2, 0x8(x0)
add x3, x1, x2
sw x3, 0x10(x0)
RISC-V 加载和存储指令
由于一些很好的技术原因,RISC-V 指令集架构不允许我们直接将内存地址写入指令。我们需要以 <基址, 偏移量> 的形式指定地址:
- 基址始终存储在一个寄存器中。
- 偏移量是一个小常数。
- 格式示例:
lw dest, offset(base)或sw src, offset(base)。
汇编示例中的行为如下:
lw x1, 0x4(x0) // x1 <- load(Mem[x0 + 0x4])
lw x2, 0x8(x0) // x2 <- load(Mem[x0 + 0x8])
add x3, x1, x2 // x3 <- x1 + x2
sw x3, 0x10(x0) // store(Mem[x0 + 0x10]) <- x3
常量和指令编码限制
- 指令被编码为 32 位。
- 需要指定操作码(10位)。
- 需要指定2个源寄存器(10位)或1个源寄存器加上一个小常数。
- 需要指定1个目的寄存器(5位)。
- 指令中的常数必须小于12位;更大的常数需要存储在内存或寄存器中并显式使用。
- 正是由于这个限制,我们从不在指令中直接指定内存地址。
程序求和数组元素
假设我们有一个求和函数,计算数组 a 的所有元素之和,其中 a[0] 到 a[n-1]。假设基地址(地址 100)已经加载到寄存器 x10 中,对应的汇编代码如下:
lw x1, 0x0(x10)
lw x2, 0x4(x10)
lw x3, 0x8(x10)
... // 继续加载其它数组元素并求和
伪指令
- 伪指令是简化汇编编程的别名,它们映射到实际的汇编指令。
- 例如,
mv x2, x1伪指令等价于addi x2, x1, 0汇编指令。
- 例如,
| 伪指令 | 等效汇编指令 |
|---|---|
mv x2, x1 | addi x2, x1, 0 |
ble x1, x2, label | bge x2, x1, label |
bgez x1, label | bge x1, x0, label |
bnez x1, label | bne x1, x0, label |
j label | jal x0, label |
负数的编码
- 表达负数的方式包括符号大小表示法和二进制补码表示法。
符号大小表示法
- 我们使用符号大小表示法来表达十进制数,用 "+" 和 "-" 分别代表正负号。
- 例如:对于二进制数
11111110000,0表示 "+",1表示 "-",这表示 -2000。 - 这种编码可能会有哪些问题?会有两种表示方式表示 0(+0 和 -0),而且为加减法设计电路比无符号数复杂。
寻找更好的编码方法
- 你能否简单地重新标记一些数字,以保留模数运算的好属性?答案是肯定的。
例如:
-1用111表示-2用110表示-3用101表示-4用100表示- 这就是所谓的二进制补码编码。
二进制补码编码
- 在二进制补码编码中,N 位数的最高位用于表示符号(正数为 0,负数为 1)。
- 二进制补码的形式:
v = -2^N-1*b_N-1 + Σ (b_i*2^i) for i = 0 to N-2 - 负数的最高位是“1”。
- 最负数是
10...000 -> -2^N-1 - 如果所有位都是 1,则是
-1。 - 指令中编码的常量使用二进制补码编码。
Take home
- 用 6 位二进制补码表示 -4。
- 将下面的代码片段翻译成 RISC-V 汇编:
sum = 0;
for (i = 0; i < 10; i++) {
sum = sum + i;
}
end
L03 Compiling Code, Procedures, and Stacks
MIT 6.004 Spring 2019 L03 Compiling Code, Procedures, and Stacks,由Silvina Hanono Wachman讲述。
本次讲座继续深入讨论了如何将高级编程语言转换成汇编语言,并开始探索如何处理程序(Procedures)。
主要内容
-
指令集回顾
到目前为止,学习了几种RISC-V指令集架构中的指令类型:
- 计算指令(ALU操作),包括寄存器-寄存器操作和寄存器-立即数操作
- 控制流指令,包括无条件跳转和条件分支
- 加载和存储指令,用于在内存和寄存器之间传输信息
- 新引入了加载上半部分立即数(Load Upper Immediate)指令,以解决常量大小的限制问题。
-
C语言到汇编语言转换
详细讲解了将C语言代码转换成汇编语言的步骤,包括变量到寄存器的分配、将复杂操作分解为简单操作等。
-
编译条件和循环语句
提供了方法论,解释了如何将if-then、if-then-else和while循环等高级语言构造转换为汇编语言。
-
程序(Procedures)
讨论了程序实现的关键要素,包括入口点、参数传递、局部存储和退出点。特别强调了使用栈和激活记录来管理程序调用所需的信息,以及如何处理嵌套程序调用。
-
调用约定
引入了调用约定,详细规定了哪些寄存器由调用者保存,哪些由被调用者保存。定义了专门的寄存器用于参数传递和返回值。
-
程序调用和返回示例
通过计算最大公约数(GCD)的程序示例,展示了如何实现程序的调用和返回,以及如何通过跳转和链接指令(Jump and Link)来保存和恢复程序执行的上下文。
分页知识点
RISC-V回顾
- 计算指令由算术逻辑单元(ALU)执行。
- 寄存器-寄存器指令格式为
op dest, src1, src2,其中op是操作码,dest是目标寄存器,src1和src2是源寄存器。 - 寄存器-立即数指令格式为
op dest, src1, const,其中const是立即数常量。
- 寄存器-寄存器指令格式为
- 控制流指令分为无条件跳转(
jal和jalr)和有条件比较跳转(comp src1, src2, label)。 - 加载和存储指令包括
lw dest, offset(base)和sw src, offset(base),这里的base是基址寄存器,offset是一个小的常数。 - 伪指令是其他指令的简写形式。
处理常量
- 执行
a = b + 3。假设a在寄存器x1中,b在x2中。对于12位的小常数,可以通过寄存器-立即数ALU操作来处理,例如addi x1, x2, 3。 - 执行
a = b + 0x123456。最大的12位2进制补码常数是2047(0x7FF)。使用li伪指令来将寄存器设置为较大的常数,例如通过两条指令lui x4, 0x123和addi x4, x4, 0x456来生成0x123456。lui指令将0x123放置到寄存器x4的高位,而addi则将0x456加到x4中。 li伪指令也可以用来处理小常数。
编译简单表达式
-
将变量分配给寄存器。
-
将运算符翻译为计算指令。
-
使用寄存器-立即数指令来处理含有小常数的操作,如
addi。 -
使用
li伪指令来处理大常数。 -
例如,C代码
int x, y, z; y = (x + 3) | (y + 123456); z = (x * 4) ^ y;对应的RISC-V汇编代码为:
// x: x10, y: x11, z: x12 // x13, x14 used for temporaries addi x13, x10, 3 li x14, 123456 add x14, x11, x14 or x11, x13, x14 slli x13, x10, 2 xor x12, x13, x11- 这段汇编代码首先将
x加 3 然后存储在x13中,将y加上123456并与x13进行或操作后存储回y(即x11)。接着,它将x左移2位(相当于乘以4)存储在x13中,然后将结果与y进行异或操作后存储到z(即x12)。
- 这段汇编代码首先将
编译条件语句
if语句
-
在C语言中的
if语句可以通过使用分支指令编译到RISC-V汇编语言中。 -
C语言示例和对应的RISC-V汇编示例如下:
if (expr) { if-body }编译为:
// 将表达式expr编译到xN寄存器中 beqz xN, endif // 编译if-body部分 endif:- 这里
beqz是分支指令,它检查寄存器xN中的值是否为0,如果为0,则跳转到endif标签。 endif是一个标签,用于在编译if-body之后标记代码的结束位置。
- 这里
if-else语句
-
if/else语句的编译与if语句类似,但需要处理两种情况(if-body和else-body)。 -
C语言示例和对应的RISC-V汇编示例如下:
if (expr) { if-body } else { else-body }编译为:
// 将表达式expr编译到xN寄存器中 beqz xN, else // 编译if-body部分 j endif else: // 编译else-body部分 endif:- 如果表达式
expr计算结果为假(即xN为0),程序会跳转到else标签,执行else-body部分;否则执行if-body部分后跳过else-body。
- 如果表达式
编译循环
while循环
-
while循环可以使用反向分支来编译。 -
C语言示例和对应的RISC-V汇编示例如下:
while (expr) { while-body }编译为:
while: // 将表达式expr编译到xN寄存器中 beqz xN, endwhile // 编译while-body部分 j while endwhile:- 在此示例中,
beqz指令检查xN是否为0,如果为0则跳转到endwhile标签,表示循环结束。如果不为0,则继续执行while-body部分,然后跳回到while标签处,重新评估循环条件。
- 在此示例中,
整合所有内容
综合示例
-
上述的循环和条件语句可以结合起来编译更复杂的结构。
-
C语言示例和对应的RISC-V汇编示例如下:
while (x != y) { if (x > y) { x = x - y; } else { y = y - x; } }编译为:
// x: x10, y: x11 j compare loop: // 编译while-body部分 compare: bne x10, x11, loop- 在这个例子中,
bne指令用来比较x10和x11,如果它们不相等(即x != y),则跳回loop标签继续执行循环体。
- 在这个例子中,
下面部分展示了如何将一个包含while循环和if-else条件语句的复杂C语言代码块转换为RISC-V汇编代码。
C代码示例:
while (x != y) {
if (x > y) {
x = x - y;
} else {
y = y - x;
}
}
对应的RISC-V汇编代码:
// x: x10, y: x11
j compare
loop:
ble x10, x11, else
sub x10, x10, x11
j endif
else:
sub x11, x11, x10
endif:
compare:
bne x10, x11, loop
这段汇编代码首先跳转到compare标签来检查循环条件。如果x <= y(ble指令),则跳转到else分支。在if分支中,x减去y的结果存回x(sub x10, x10, x11),否则else分支中y减去x的结果存回y(sub x11, x11, x10)。结束if或else分支后,跳回到compare以重新检查循环条件。
过程
过程定义:
- 过程(也称为函数或子程序)是执行特定任务的可重用代码片段,具有单一的命名入口点和零个或多个形式参数。当过程执行完毕后,它会返回到调用者。
- 使用过程可以实现抽象和重用,允许从简单过程的集合中组成大型程序。
C代码示例:
int gcd(int a, int b) {
int x = a;
int y = b;
while (x != y) {
if (x > y) {
x = x - y;
} else {
y = y - x;
}
}
return x;
}
对应的RISC-V汇编代码:
// x: x10, y: x11
j compare
loop:
ble x10, x11, else
sub x10, x10, x11
j endif
else:
sub x11, x11, x10
endif:
compare:
bne x10, x11, loop
这段代码定义了一个计算两个整数最大公约数(GCD)的函数。函数体的汇编代码与前面的循环几乎相同,因为核心逻辑是类似的。函数最终返回x,在汇编中通常使用a0(或x10)寄存器来返回值。
管理过程的寄存器空间
- 当一个过程(调用者)调用另一个过程(被调用者)时,它们共享同一套寄存器集。
- 如果按照某种约定来划分调用者和被调用者之间的寄存器,当多个过程相互调用时会非常复杂,且寄存器本身就很稀缺。
- 更好的解决方案是,调用者不应该依赖于被调用过程如何管理其寄存器空间。
- 调用者或被调用者应该将调用者的寄存器保存在内存中,并在过程调用完成后恢复这些寄存器值。
通过这种方式,RISC-V汇编确保每个过程可以在不干扰其他过程的情况下运行。
实现过程
- 调用者需要通过寄存器向被调用的过程传递参数并从被调用的过程获取结果。
- 一个过程可以从多个不同位置被调用。调用者可以通过执行一个无条件跳转指令到达被调用的过程代码。
- 然而,为了返回到调用过程中的正确位置,被调用的过程需要知道它应该使用哪个返回地址。因此,返回地址必须被保存并传递给被调用的过程。
过程链接
-
控制权如何在调用者和被调用者之间传递?
-
使用
jal ra, label(跳转并链接)指令,该指令做了以下事情:
- 在返回地址寄存器
ra中存储proc_call指令后面第四个字节的地址。 - 跳转到标签
label处的指令,这里的label是过程的名称。 - 在执行完过程后,使用
j ra(跳转到ra寄存器中的地址)返回到调用者并继续执行。
- 在返回地址寄存器
-
过程调用的复杂性
- 如果一个过程A调用了过程B,过程B又调用了过程C,那么单一的返回地址寄存器是不够用的;过程C的返回地址将会覆盖过程A的返回地址。
- 在存储过程A的寄存器的内存空间中也存在类似的复杂性——这个空间必须与存储过程B寄存器的空间不同。
过程的存储需求
- 过程调用的基本要求包括输入参数、返回地址和结果。
- 局部存储需求包括:
- 编译器无法放在寄存器中的变量。
- 保存我们将要覆写的调用者寄存器值的空间。
每次过程调用都会有它自己的所有这些数据的实例,这被称为过程的激活记录(activation record)。
栈的洞察
- 栈是一种数据结构,用于存储激活记录(activation records)。
- 激活记录按照后进先出(LIFO)的顺序被分配和释放。
- 栈的操作包括push(压入)、pop(弹出)以及访问栈顶元素。
- 我们只需要访问当前正在执行的过程的激活记录。
RISC-V栈
- 栈位于内存中,需要一个寄存器来指向它。在RISC-V中,栈指针
sp是寄存器x2。 - 栈的增长方向是向下的,即从高地址向低地址增长。
- 执行push操作会减小栈指针
sp的值。 - 执行pop操作会增加栈指针
sp的值。
- 执行push操作会减小栈指针
sp寄存器指向栈顶,即最后一个压入栈的元素。- 使用栈的规则是:可以在任何时候使用栈,但在使用完毕后要恢复到原始状态。
使用栈
-
示例的入栈序列:
addi sp, sp, -N sw ra, 0(sp) sw a0, 4(sp) -
对应的出栈序列:
lw ra, 0(sp) lw a0, 4(sp) addi sp, sp, N这些操作分别表示在进入和退出过程时保存和恢复寄存器,以及分配和释放栈空间。
入栈序列好像有些混淆?先
sw a0, 4(sp)才更符合LIFO吧,又或者属于同一次的入栈不用在意顺序。
调用约定
-
调用约定指定了过程间寄存器使用的规则。
-
RISC-V调用约定为寄存器
x0-x31提供了符号名称以指明它们的作用:a0到a7(x10到x17):用于函数参数。a0和a1(x10和x11):用于函数返回值。ra(x1):用于返回地址。t0到t6(x5-x7,x28-x31):用作临时寄存器。s0到s11(x8-x9,x18-x27):被保存的寄存器。sp(x2):栈指针。gp(x3):全局指针。tp(x4):线程指针。zero(x0):硬连线零。
每个寄存器的保存责任分为调用者(Caller)和被调用者(Callee),这决定了在过程调用过程中哪些寄存器需要被保存和恢复。
通过这样的约定,不同的过程可以预知哪些寄存器在调用后会被保留其值,哪些寄存器可能会被修改,从而在编写代码时可以做出适当的寄存器使用决策。
调用者保存与被调用者保存寄存器
- 调用者保存寄存器:在函数调用时不保留。如果调用者希望保持其值不变,它必须在将控制权交给被调用者之前将其保存在栈上。通常,这包括参数寄存器(
aN),返回地址(ra),和临时寄存器(tN)。 - 被调用者保存寄存器:在函数调用时必须保留。如果被调用者希望使用这些寄存器,它必须在使用前将其原始值保存在栈上,并在返回控制权给调用者之前恢复它们。这通常包括已保存的寄存器(
sN)和栈指针(sp)。
使用被调用者保存寄存器的例子
在这个例子中,函数f用到了两个被调用者保存寄存器s0和s1来存储临时值。在函数调用的开始,这些寄存器的值被保存到了栈上。函数完成后,这些值从栈上恢复,以保证这些寄存器的值在函数调用前后保持不变。
使用调用者保存寄存器的例子
这个例子展示了一个调用者如何保存和恢复寄存器的值。在这种情况下,调用者需要保证在调用另一个函数前保存a1寄存器的值,因为被调用的函数可能会修改a1寄存器的内容,调用者在调用之后可能还需要用到a1寄存器原来的值。
栈的使用示例
提供了在调用函数前、调用函数时和调用函数后栈的状态的视图。这帮助我们可视化如何在栈上分配和释放空间,并显示在函数调用期间如何保持寄存器s0和s1的值。
这些概念在函数调用过程中确保了变量的正确保存和恢复,这对于编写可以预测并一致地运行的程序至关重要。在编程和调试过程中,了解这些细节可以帮助理解函数调用可能出现的错误和行为异常。
补充
这里是一些关于在RISC-V架构中进行函数调用和栈操作的关键知识点总结:
- 调用约定:在RISC-V及许多其他体系结构中,调用约定定义了函数参数、返回值、和临时变量应如何在寄存器和栈之间传递。对于RISC-V,默认的调用约定规定了
a0到a7用于前八个整数函数参数,a0和a1用于前两个返回值。 - 寄存器使用:RISC-V的调用约定还规定了哪些寄存器需要在函数调用前保存(caller-saved)和哪些寄存器需要在函数返回前保存(callee-saved)。
- 栈的后进先出(LIFO)原则:在函数调用时,最后压入栈的数据最先被弹出。保存寄存器值时,栈指针(
sp)下移以分配空间,然后寄存器值依序压入。恢复寄存器值时,栈中的数据依序弹出,并且栈指针上移以释放空间。 - 寄存器的保存与恢复:通常,
ra(返回地址寄存器)和函数参数(如果后续函数调用会更改它们)需要被保存在栈上。如果一个函数调用另一个函数,ra需要首先保存,以确保能够返回到正确的位置。 - 寄存器保存的必要性:如果一个函数(比如
multiply)不会调用任何会更改a0或a1的函数,则在调用该函数之前不需要在栈上为这些寄存器分配空间。 - 栈指针的管理:函数调用前后,栈指针的位置应该保持一致。这意味着分配给栈帧的空间在函数返回前必须完全释放。
在嵌套函数调用的情况下,每一层函数都必须确保它调用的任何函数不会意外地改变它依赖的寄存器值。如果存在这种可能性,函数必须在调用之前将这些寄存器值保存在栈上,并在调用结束后从栈上恢复它们。
函数调用时保存寄存器的必须遵循LIFO原则的情况
- 当一个函数可能再调用另一个函数(即有嵌套函数调用)时,必须保存当前函数的返回地址
ra。在这种情况下,LIFO原则非常重要,因为每个函数都需要在完成后能够返回到正确的位置。 - 如果
sum函数或任何被调用的函数内部可能会导致ra寄存器被修改(比如通过另一个函数调用),那么在恢复寄存器时就必须严格遵守LIFO原则,首先恢复最后保存的寄存器,这通常是ra。
在这种情况下,如果不遵守LIFO原则,可能会导致返回到错误的地址,从而导致程序运行错误或崩溃。
在没有嵌套调用的情况下,为何可以灵活恢复寄存器
- 当
sum函数调用完成后,ra没有被更改,因此可以安全地先恢复其他寄存器,例如a1。这是因为ra的值在栈上保持不变,没有被sum函数或其他任何操作修改。 sp(栈指针)保持不变,因此恢复寄存器的顺序可以灵活安排。只要所有必须的寄存器最终都被正确恢复,并且栈指针也被正确调整到函数调用前的状态,程序的执行流就不会受到影响。
总结来说,是否需要遵守严格的LIFO原则取决于函数调用的上下文。如果存在修改ra的操作,那么必须遵守LIFO。如果保证ra在整个调用期间不会被修改,恢复寄存器的顺序就可以有所灵活性。在编写汇编代码时,通常建议遵循一致的模式,以减少混淆和潜在的错误。
补充2
激活帧
激活帧(Activation Frame),也称为栈帧(Stack Frame),是在栈上为每次函数调用所分配的内存块。它包含了函数执行所需的所有信息,如:
- 局部变量:函数内声明的变量。
- 参数:传递给函数的参数。
- 返回地址:函数执行完毕后应返回到的代码位置。
- 保存的寄存器:调用前需要保存的寄存器,以便函数执行后能够恢复。
栈帧
栈帧是栈上分配给单个函数调用的内存段。每次函数调用时,一个新的栈帧会被推入栈顶,每次函数返回时,其对应的栈帧会被弹出。栈帧的结构通常由编译器自动管理,确保了函数可以正确地访问它的变量和参数,以及正确返回到调用位置。
栈指针(sp)
栈指针是一个特殊的寄存器,用来指向栈顶当前的位置。在RISC-V架构中,这个寄存器通常是sp(x2)。栈指针在函数调用时移动,以分配新的栈帧,并在函数返回时恢复,以释放栈帧所占用的空间。
栈从高地址向低地址增长
大多数现代架构的栈都是“向下增长”的,意味着栈顶的地址会随着数据的推入而减小。例如,如果栈指针sp的当前地址是0x8000,在一个新的栈帧被推入栈后,sp可能会变为0x7FFC。这样,新的数据会放在之前数据的下方(即地址更小的方向)。这种设计通常是出于安全和效率的考虑。
L04 Procedures and MMIO
MIT 6.004 2019 L04 Procedures and MMIO,由Silvina Hanono Wachman讲述。
本讲座深入讲解了汇编语言中程序(Procedures)的处理,尤其是关于参数传递、内存访问以及更复杂例子的实现。
主要内容
- 程序和内存操作回顾
- 回顾了程序处理中的关键概念,如参数传递、返回值、局部变量和程序退出点。
- 强调了使用栈(Stack)和激活记录(Activation Record)来管理程序调用所需的信息。
- 激活记录 活动记录(Activation Record),常称栈帧(stack frame)。
- 内存操作详解
- 详细区分了加载(Load)和存储(Store)指令与立即数加载(Load Immediate)的不同,明确了后者并不访问内存。
- 讨论了使用栈进行数据保存和恢复的具体方法,包括如何通过调整栈指针(Stack Pointer)来保存和恢复寄存器值。
- 嵌套程序和递归程序
- 介绍了嵌套程序调用中保存返回地址(Return Address)的重要性,特别是当程序中有多层调用时如何使用栈来管理这些地址。
- 通过斐波那契数列的计算示例详细展示了如何实现递归程序。
- 使用指针传递数组
- 讨论了如何通过指针而不是直接通过值来传递数组给程序,以处理大型数据结构。
- 通过查找数组中的最大值的示例演示了如何在程序中使用指针和内存访问来处理数组数据。
- 内存布局和MMIO
- 解释了内存的不同区域(如栈、堆、静态区和代码区)以及它们的用途。
- 简要介绍了内存映射I/O(Memory-Mapped I/O,MMIO)的概念,为后续实验室内容预设背景。
- 参数传递的选择和优化
- 讨论了何时选择直接传递值与何时使用指针传递参数的考量,特别是在参数数量超出寄存器数量时的策略。
分页知识点
程序和MMIO(内存映射输入输出)
li, lui, 和mv指令与lw指令的区别
这一部分对RISC-V指令进行了澄清:
li(load immediate)和lui(load upper immediate)指令不涉及内存操作。它们是立即数加载指令,直接将常量编码到指令中:li a1, 2:将立即数2加载到寄存器a1中。li a1, 0x12345:将立即数0x12345加载到寄存器a1中。lui a1, 2:将立即数2加载到寄存器a1的上半部分。mv(move)指令也不是内存操作。它用于将一个寄存器的内容复制到另一个寄存器:mv a1, a0:将寄存器a0的内容复制到寄存器a1中。
lw和sw指令对内存的引用
这里解释了lw(load word)和sw(store word)是内存操作指令:
lw用于从内存加载一个字(32位)到寄存器。sw用于将寄存器的内容存储到内存中。
示例中展示了正确和错误的用法:
- 正确:要将
a0的结果存储到a2中,应该使用mv指令,然后用sw存储到内存。 - 错误:不能直接使用
add指令将a0的内容加到内存地址。
激活帧和过程调用的回顾
总结激活帧(activation frames)常称栈帧(stack frame)和程序调用的概念:
- 激活帧包含了程序调用的数据,例如参数、返回地址和局部或临时变量。
- 当调用程序时,在内存中分配一个新的激活帧;程序退出时,激活帧被释放。
- 激活帧以栈的方式分配,即遵循LIFO原则。
- 当前程序的激活帧总是在栈顶。
激活帧结构
编译器使用一致的栈帧约定:
- 调用过程前:栈上有未使用的空间,
sp指向栈顶。 - 过程调用期间:在栈上分配了激活帧,包括局部变量(如果有的话)、保存的寄存器(如果有的话)、保存的返回地址
ra和保存的参数寄存器(如果有的话)。 - 过程调用后:激活帧被释放,回到了只有未使用空间的状态。
使用栈的回顾
栈的内容包括:
- 推入前(Before push):栈上有未使用的空间,
sp指向栈顶。 - 推入后(After push):
ra和a0被保存在栈上,sp更新为指向新的栈顶。 - 弹出后(After pop):
ra和a0已经从栈上恢复,sp恢复为原来的位置。
示例推入(push)序列:
addi sp, sp, -8
sw ra, 0(sp)
sw a0, 4(sp)
示例弹出(pop)序列:
lw ra, 0(sp)
lw a0, 4(sp)
addi sp, sp, 8
RISC-V栈的回顾
- 栈存在于内存中,栈从高地址向低地址增长。
sp指向栈顶,即最后推入的元素。- 推入序列通常涉及减小
sp,然后用sw指令存储数据。 - 弹出序列则是用
lw指令恢复数据,随后增加sp的值。
栈的纪律:
- 可以在任何时候使用栈,但是要留下原样。
RISC-V寄存器的回顾
列出了寄存器的象征性名称、寄存器号、描述,以及是调用者(caller)还是被调用者(callee)负责保存的信息。
a0 to a7:寄存器x10至x17,用于存放函数参数。保存者是调用者(caller)。a0 and a1:寄存器x10和x11,用于存放函数的返回值。保存者也是调用者(caller)。ra:寄存器x1,用于存放函数的返回地址。保存者是调用者(caller)。t0 to t6:寄存器x5-7, x28-31,作为临时寄存器。保存者是调用者(caller)。s0 to s11:寄存器x8-9, x18-27,作为需要被保存的寄存器,以便在函数调用后恢复原值。保存者是被调用者(callee)。sp:寄存器x2,作为栈指针,指向栈顶的地址。保存者是被调用者(callee)。gp:寄存器x3,作为全局指针。tp:寄存器x4,作为线程指针。zero:寄存器x0,是一个固定的零寄存器,总是返回零值。
在设计函数和过程调用的时候,编程者需要遵循这个约定,确保正确使用每个寄存器,以及在函数调用过程中正确保存和恢复这些寄存器的值。
调用约定回顾
调用者(Caller):在函数调用之前保存ra(返回地址)寄存器到栈上,并在函数返回后恢复。如果有aN寄存器需要在过程调用后继续使用,也要进行保存和恢复。
被调用者(Callee):在使用sN寄存器之前,要先保存它们原始的值,并在函数退出前恢复。在退出函数时,还需要恢复栈指针sp到其原始值。
一个函数示例:
# 调用函数
addi sp, sp, -4
sw s0, 0(sp)
...
lw s0, 0(sp)
addi sp, sp, 4
ret
# 函数本身
func:
addi sp, sp, -4
sw s0, 0(sp)
...
lw s0, 0(sp)
addi sp, sp, 4
ret
嵌套程序调用
如果一个过程调用了另一个过程,它需要保存自己的返回地址。请记住ra是调用者保存的。
例如,一个判断两个数是否互质的函数coprimes调用了gcd函数:
coprimes:
addi sp, sp, -4
sw ra, 0(sp) # 保存 ra
call gcd # 调用 gcd
addi a0, a0, -1
sltiu a0, a0, 1
lw ra, 0(sp) # 恢复 ra
addi sp, sp, 4
ret
在这段RISC-V汇编代码中,coprimes是一个函数,其目的是调用另一个函数gcd,并使用gcd的结果来确定两个数是否互质(即最大公约数是否为1)。下面是对关键部分代码的逐行解释:
addi sp, sp, -4 # 在栈上分配4字节空间
sw ra, 0(sp) # 将ra(返回地址)保存到栈上
call gcd # 调用gcd函数
addi a0, a0, -1 # 将gcd函数的返回值(存储在a0)减1
sltiu a0, a0, 1 # 检查a0是否小于1(无符号比较),并将结果存入a0
lw ra, 0(sp) # 从栈上恢复ra(返回地址)
addi sp, sp, 4 # 释放栈上的空间
ret # 返回到调用函数的地方
具体到addi a0, a0, -1和sltiu a0, a0, 1这两行:
addi a0, a0, -1:这行代码将寄存器a0中的值减去1。因为a0在调用gcd之后包含gcd的返回值,如果gcd返回的是1(意味着两个数互质),那么执行这条指令后a0将变成0。sltiu a0, a0, 1:这条指令进行无符号的比较。它检查寄存器a0中的值是否小于1,并将比较结果设置为1或0,存入a0中。这样,如果gcd返回的是1(两个数互质),上一条指令会将a0减到0,然后这条指令将a0设置为1,反之如果gcd返回不是1(不互质),a0已经是非零值,这条指令将a0设置为0。
总结来说,这两条指令一起用来检查gcd函数返回的是否是1。如果是1,说明输入的两个数互质,a0将被设置为1,表示真;如果不是1,说明不互质,a0将被设置为0,表示假。这个结果将作为coprimes函数的返回值。
这种实现的一个原因可能是作者希望确保coprimes函数返回的是一个明确的布尔值1或0,而不仅仅是依赖gcd可能返回的任何非1值。虽然直接与2比较也可以达到检测互质的效果,但这样做不会得到一个明确的布尔值。例如:
- 如果
gcd返回2,那么sltiu a0, a0, 2将会把a0设置为0,因为2不小于2。 - 但如果
gcd返回的是任何大于2的值,sltiu a0, a0, 2依然会将a0设置为0,这不会告诉你gcd的确切返回值,只告诉你它不是1。
在某些编程实践中,为了代码的清晰性和一致性,作者可能更偏好返回明确的布尔值。所以通过这种方式减1然后比较是否小于1,可以保证无论gcd返回什么,coprimes的返回值总是一个确切的布尔标志。
递归程序
递归程序可以看作是嵌套程序的一个特例。例如,一个计算斐波那契数的递归函数:
计算第n个斐波那契数的伪代码:
# 假设 n > 0
# 如果 n 为 0 或 1,返回 n
# 否则,返回 fib(n-1) + fib(n-2)
# 这里指令的顺序对于程序的正确行为非常关键
fib:
li t0, 2
blt a0, t0, fib_done
addi sp, sp, -8
sw s0, 0(sp) # 保存 s0
mv s0, a0 # 保存 n
call fib # 计算 fib(n-1)
mv s1, a0 # 保存 fib(n-1)
addi a0, s0, -2
call fib # 计算 fib(n-2)
add a0, s0, a0
lw s0, 0(sp) # 恢复 s0
addi sp, sp, 8
fib_done:
这段代码是一个实现斐波那契数列的递归函数,我们逐行解释如下:
li t0, 2:将临时寄存器t0加载为常数2。blt a0, t0, fib_done:如果寄存器a0(包含当前fib调用的参数n)小于2,则跳转到fib_done标签。这实现了函数的基础情况:如果n为0或1,则不需要递归,函数可以直接返回n的值。addi sp, sp, -8:分配8字节的堆栈空间来保存寄存器(因为每个寄存器都是64位,即8字节)。sw s0, 0(sp):将保存的寄存器s0的当前值存储在栈上。这是因为s0将在此函数的递归调用中被用作临时寄存器。mv s0, a0:将当前的n值(斐波那契数列中的位置),从a0移动到s0,以便后续调用fib。call fib:递归调用fib(n-1)。mv s1, a0:将递归调用返回的结果fib(n-1),从a0移动到另一个保存寄存器s1中。addi a0, s0, -2:准备下一个递归调用的参数,计算n-2并存入a0。call fib:递归调用fib(n-2)。add a0, s0, a0:将fib(n-1)和fib(n-2)的结果相加。这时s0包含fib(n-1)的值,a0包含fib(n-2)的结果。结果存回a0,为返回值做准备。lw s0, 0(sp):从栈中恢复保存的寄存器s0的值。addi sp, sp, 8:将栈指针sp移回之前的位置,反向执行步骤3的操作,释放之前分配的栈空间。fib_done:如果a0小于2,就跳转到这里。在此标签处,简单返回a0(在递归调用的基础情况中,它包含n的值,即0或1)。
整个函数的正确性依赖于寄存器的保存和恢复,以及栈的正确管理。对于递归函数来说,每次递归调用之前,需要保存当前状态(保存寄存器s0),递归调用后需要恢复它,以便进行下一个递归调用或返回结果。这是因为递归函数每次调用都需要一个独立的栈帧来保存其局部变量和状态。
处理大型数据结构
假设我们想要写一个过程 vadd(a, b, c) 来将两个数组 a 和 b 相加,并将结果存储在数组 c 中。假设数组太大,不能完全存储在寄存器中。
我们将逐个将 a 和 b 的元素搬运到寄存器中,相加后再存储回内存。
由于 vadd 可以用不同的参数被调用,我们需要考虑如何从调用过程将参数传递给 vadd。这需要调用者和被调用者约定如何通过栈传递大型数据结构的信息。
向过程传递数组
- 我们可以将数组分成大小为k的块,这些块足够小,可以适配寄存器,并且可以由vadd过程来添加这两个小块数组。当然,调用者需要调用这个过程n/k次来添加所有元素!
- 更好的方式是将a,b和c的基地址传递给过程,并让它直接访问内存。
- 这与我们迄今为所见的情况有很大不同,因为被调用的过程可以访问其激活帧之外的内存。
过程 vadd(a, b, c) 中,我们需要处理的大型数据结构(如大型数组)的基地址被传递给过程。在这种情况下,过程会根据基地址和元素索引计算出每个元素的确切内存地址,然后使用 lw 指令将这些元素加载到寄存器中,执行必要的算术操作,最后使用 sw 指令将结果写回内存。
这里提到的“将基地址传递给过程”其实就是将数组的起始内存地址传递给过程,这样过程就可以根据这个地址和偏移量来直接访问内存中的每个元素。这是一种间接寻址的方式,它允许过程通过偏移量计算来定位数组的每个元素,而无需将整个数组复制到过程的激活帧中。简单来说,过程得到的是一个指针,指向数组的首个元素所在的内存地址。
例如,如果有一个过程 vadd(a, b, c) 被调用,并且参数 a, b, c 分别是数组 A, B, C 的起始地址,过程可以像下面这样访问数组 A 的第 i 个元素:
# 计算 A[i] 的地址
add t0, a0, t1 # t1 中存储了 i * sizeof(element)
# 加载 A[i] 到寄存器
lw t2, 0(t0) # t2 现在包含了 A[i] 的值
这里 a0 是寄存器,包含了数组 A 的起始地址,而 t1 是另一个寄存器,包含了所需元素的索引乘以该元素类型所占的字节数(偏移量)。过程会用 lw 指令来加载实际的数组元素到另一个寄存器 t2 中,进行运算,然后可能再使用 sw 将结果写回到数组 C 中。这样的操作会在整个数组上循环进行,直到所有元素被处理完毕。
RISC-V内存布局
- 主存中的文本(代码)、静态和堆区域是连续放置的,从低地址开始。
- 堆向更高地址增长。
- 栈从最高地址开始,向更低地址增长。
sp(栈指针)指向栈顶。gp(全局指针)指向静态区域的起始。
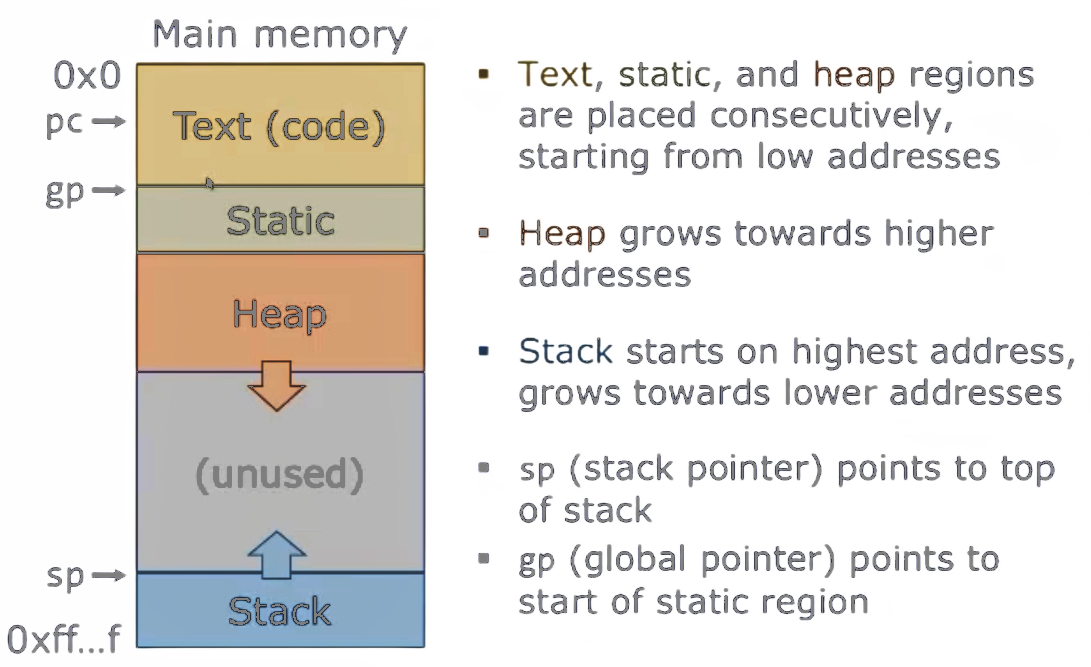
- 大多数编程语言(包括C)有三个独立的内存区域用于数据:
- 栈:存储过程调用使用的数据。
- 静态:持有程序整个生命周期内的全局变量。
- 堆:存储动态分配的数据。
- 在C中,程序员手动管理堆,使用
malloc()分配新数据,并用free()释放。 - 在Python、Java和大多数现代语言中,堆是自动管理的。程序员创建新对象(例如,在Python中的
dict()),但系统只有在安全释放它们(没有指针指向它们时)才会释放它们。
- 在C中,程序员手动管理堆,使用
- 另外,文本区域存储程序代码。
作为参数传递复杂数据结构
- 寻找数组中最大元素的示例函数:
- C 语言代码:
// 在大小为size的数组a中找到最大的元素
int maximum(int a[], int size) {
int max = 0;
for (int i = 0; i < size; i++) {
if (a[i] > max) {
max = a[i];
}
}
return max;
}
int main() {
int ages[5] = {23, 4, 6, 81, 16};
int max = maximum(ages, 5);
}
- RISC-V 汇编语言实现:
maximum:
mv t0, zero // t0: i 初始化为 0
mv t1, zero // t1: max 初始化为 0
j compare // 跳转到比较标签
loop:
slli t2, t0, 2 // t2: i*4,计算数组索引 i 对应的字节偏移量
// t3: addr of a[i],计算 a[i] 的内存地址
add t3, a0, t2
lw t4, 0(t3) // t4: a[i],从内存加载 a[i] 的值
ble t4, t1, endif // 如果 a[i] 小于等于 max,则跳到 endif
mv t1, t4 // max = a[i],更新最大值
endif:
addi t0, t0, 1 // i++
compare:
blt t0, a1, loop // 如果 i < size,则继续循环
mv a0, t1 // a0 = max,将最大值移到返回值寄存器
ret // 返回到调用者
在汇编代码中,程序首先初始化循环变量 i(寄存器 t0)和最大值变量 max(寄存器 t1)为0。然后,进入主循环之前,执行比较来判断是否继续循环。循环体中使用左移操作(slli)和加法来计算数组元素的内存地址,加载元素值(lw),比较当前元素值是否大于已知的最大值,如果大于,更新最大值。循环后,如果索引小于数组大小,程序将回到循环的开始。循环结束后,将找到的最大值放入 a0 寄存器,这是 RISC-V 中用于返回函数结果的寄存器,并返回到调用者。
主函数 main 初始化一个名为 ages 的数组并调用 maximum 函数来找到数组中的最大值并存储在变量 max 中。在汇编中,数组 ages 的基地址通过寄存器 a0 传递给 maximum 函数,而数组的大小则通过寄存器 a1 传递。这样,maximum 函数就可以直接访问和操作内存中的数组元素。
为什么不总是使用指针作为参数?
// 计算三角形的周长
int perimA(int a, int b, int c) {
int res = a + b + c;
return res;
}
// 计算多边形的周长
int perimB(int sides[], int size) {
int res = 0;
for (int i = 0; i < size; i++) {
res += sides[i];
}
return res;
}
间接寻址可以是昂贵的:
- 需要额外的内存引用。
- 执行速度可能较慢。
传递复杂数据结构作为参数或返回值
- 其他复杂的数据结构,比如字典、结构体、链表等,将遵循同样的方法,即通过指针将数据结构作为参数传递给过程,同时提供所需的其他信息,如元素数量等。
- 类似地,当返回值是一个复杂的数据结构时,该数据结构存储在内存中,过程返回一个指向该数据结构的指针。
Take home
- 讨论如果一个过程需要10个参数(即,参数数量多于寄存器可以存放的数量),应该如何实现。
在解释如何处理超过寄存器能存储的参数数量的过程时,如果一个过程需要的参数超出了可用的参数寄存器数目,那么这些参数需要通过栈来传递。调用者会在调用过程之前,把超出寄存器数量的参数推入栈中。被调用过程(callee)则可以通过访问栈来读取这些参数值。
如何在汇编中处理输入和输出?
- 内存映射I/O(Memory Mapped I/O)
- 使用相同的地址空间来映射内存和I/O设备。
- I/O设备监控CPU内存请求并对使用I/O设备关联地址的内存请求做出响应。
- MMIO地址只能用于I/O,不能用于常规存储。
MMIO地址
- 输出(Outputs):
0x4000 0000- 执行sw到这个地址会在控制台打印一个ASCII字符,对应于此地址存储的值的ASCII等价值。0x4000 0004- 执行sw到这个地址会打印一个十进制数字。0x4000 0008- 执行sw到这个地址会打印一个十六进制数字。
- 输入(Inputs):
0x4000 4000- 执行lw从这个地址会从控制台读取一个有符号字。- 重复执行
lw到这个地址会读取下一个输入字等等。
内存映射I/O是一种机制,允许CPU通过读写特定的内存地址来与外设进行数据交换,而不需要特殊的I/O指令。输出地址映射到外设,用于发送数据,而输入地址用于接收数据。这种方式使得I/O操作对于程序来说就像访问内存一样简单。
在RISC-V汇编中,这意味着可以使用普通的内存访问指令(如 lw 和 sw)与硬件设备进行通信,而这些设备会响应这些特定地址上的读写操作。
内存映射I/O示例 1
// 加载读取端口到t0
li t0, 0x40004000
// 读取第一个输入
lw a0, 0(t0)
// 读取第二个输入
lw a1, 0(t0)
// 把它们相加
add a0, a0, a1
// 加载写入端口到t0
li t0, 0x40000004
// 写出结果
sw a0, 0(t0)
内存映射I/O示例 2
// 准备从控制台读取输入
li t0, 0x40004000
// 获取用户输入
lw a0, 0(t0)
// 再次获取用户输入
lw a1, 0(t0)
// 启动性能计数器,将1存储到特定地址
li t1, 0x40006000
sw t2, 0(t1)
// 把输入相加
add a0, a0, a1
// 停止性能计数器,将0存储到特定地址
sw zero, 0(t1)
// 准备将结果打印为十进制数
li t0, 0x40000004
// 打印和
sw a0, 0(t0)
// 从性能计数器获取计数
lw t2, 0(t1)
// 打印计数
sw t2, 0(t0)
MMIO用于性能度量
-
性能度量:
-
0x4000 5000:执行加载指令(lw)从该地址可以获取从程序执行开始的指令计数。 -
0x4000 6000:执行加载指令(lw)从该地址可以获取打开和关闭性能计数器之间的指令数量。 -
0x4000 6004:- 执行存储指令(
sw)并向该地址写入0,可以关闭性能计数器。 - 执行存储指令(
sw)并向该地址写入1,可以打开性能计数器。
- 执行存储指令(
-
在示例1中,MMIO被用于从I/O端口读取数据并将数据写入I/O端口。在示例2中,除了读取和写入外,还展示了如何使用MMIO地址监控程序的性能,例如计算指令数量。这两个例子都展示了MMIO如何让汇编程序能够与硬件I/O设备进行交互,这对于嵌入式系统和操作系统级别的编程非常关键。
回顾
- 程序和调用约定:
- 程序通常需要通过调用函数来执行复杂的任务,这些调用遵循特定的规则集,即调用约定。
- 调用约定定义了如何在寄存器中传递参数,哪些寄存器需要保存(caller-saved)和恢复(callee-saved),以及栈的使用方式。
- 当函数需要的参数数量超过寄存器能够容纳的数量时,额外的参数通常通过栈传递。
- 递归和嵌套函数调用:
- 递归函数是自己调用自己的特殊函数,它们是嵌套函数调用的一个例子。
- 在嵌套或递归调用中,保持调用链的完整性至关重要,这通常涉及到在栈上管理激活记录(activation records),确保每次函数调用都有其自己的状态空间。
- 内存映射I/O(MMIO):
- MMIO是一种将设备寄存器映射到内存地址空间的技术,使得程序可以通过标准的内存访问指令来读取和写入这些设备寄存器。
- MMIO使程序能够通过使用
lw(load word)和sw(store word)指令与I/O设备交互。
- MMIO的性能度量应用:
- 特定的MMIO地址可以用来访问性能计数器,例如指令计数器,这可以帮助监控和优化程序性能。
- 通过写入特定的MMIO地址,程序可以开启或关闭性能计数器,获取执行指令的数量等信息。
- MMIO示例:
- 在给出的示例中,展示了如何使用MMIO读取控制台输入和输出到控制台,以及如何使用MMIO地址进行性能监控。
总体来说,这些概念为理解程序在低级别如何运行提供了重要的基础,特别是在涉及函数调用的上下文中如何正确地传递参数、管理栈、以及与外部设备进行通信。MMIO的使用是嵌入式系统和驱动程序开发中特别常见的,它使得软件能够直接与硬件交互。
L05-Combinational Circuits:From Boolean Algebra to Gates
MIT 6.004 2019 L05 Combinational Circuits: From Boolean Algebra to Gates,由教授Arvind讲述。
这次讲座的主题是组合电路,从布尔代数到门电路的转换。
主要内容
-
课程结构回顾:讲座开始时,教授回顾了课程的结构,提到第一模块已经完成,主要讲授了汇编语言编程,现在进入第二模块,即逻辑设计。
-
逻辑设计:在接下来的八次讲座中,学生将学习逻辑设计的各个方面,特别强调使用Bluespec语言来表达逻辑设计,并进行实验。
-
逻辑合成:讲解了如何将高级逻辑描述转化为实际硬件门电路的过程,这一部分涉及到大量的技术细节和工具的使用。
-
组合电路基础:教授介绍了组合电路的基本概念,包括它们的输入和输出均为二进制的特性,以及它们是无状态的,即相同的输入总是产生相同的输出。
-
基本逻辑门:详细介绍了包括NOT门(非门)、AND门(与门)、OR门(或门)、NAND门(与非门)、NOR门(或非门)、XOR门(异或门)在内的基本逻辑门,以及它们的真值表和符号表示。
-
布尔表达式与真值表:讲解了如何从真值表得到布尔表达式,以及如何使用AND、OR和NOT门来构建这些表达式。
-
通用门:讨论了如何使用NAND和NOR门来表示任何布尔函数,显示了这些门的通用性。
-
半加器与全加器:讲解了二进制加法的硬件实现,包括半加器和全加器的设计和功能。
-
使用Bluespec语言:演示了如何使用Bluespec System Verilog来描述和模拟电路,这是一个针对硬件设计的高级描述语言。
总结来说,这次讲座深入探讨了从布尔代数到门电路的转换,逻辑设计的各个方面,以及如何使用现代工具和语言来实现和模拟复杂的数字逻辑电路。教授强调了理解这些基本概念的重要性,并展示了将这些理论应用于实际硬件设计中的方法。
分页知识点
组合电路:从布尔代数到门电路
- 讲师:Arvind,来自麻省理工学院的计算机科学与人工智能实验室。
- 日期:2019年2月21日。
MIT 6.004 2019年春季课程的大纲:
- 模块 1:RISC-V汇编语言编程(4讲)。
- 模块 2:数字逻辑设计(8讲),内容涵盖布尔代数、组合电路、时序电路、在Bluespec中表达逻辑设计、逻辑综合(包括将Bluespec设计转化为逻辑电路,以及将逻辑电路转化为标准的门电路库),以及并发问题。
- 模块 3:RISC-V处理器(6+1讲)。
- 模块 4:操作系统、输入/输出、虚拟内存(3讲)。
- 模块 5:多核处理器(2讲)。
组合电路:
- 组合电路有二进制的输入和输出。
- 它代表一个纯函数(pure function),例如
f: Bool × Bool × Bool → Bool × Bool,表示这个函数接受三个布尔值作为输入,输出两个布尔值。 - 它没有记忆或状态,即给定相同的输入,它总是产生相同的输出。
三种简单的组合电路:
- NOT(非)门:输入为0时输出1,输入为1时输出0。门电路符号为一个三角形带有一个小圆圈,布尔表达式表示为
s = ~a。 - AND(与)门:只有当所有输入都为1时输出才为1,否则输出为0。门电路符号为一个扁平的D形,布尔表达式表示为
s = a · b。 - OR(或)门:只要任一输入为1,输出就为1。门电路符号为一个曲线形状,布尔表达式表示为
s = a + b。
图片中的内容继续讨论了组合电路中的一些著名逻辑门,以及如何用真值表来定义组合电路的功能。内容的中文翻译和详细解释如下:
其他著名的门电路:
- NAND门:当两个输入都为1时,输出为0;其余情况输出为1。NAND门的功能可以用NOT门、AND门和OR门来表达,其布尔表达式为
s = ~(a·b)。 - NOR门:只有当两个输入都为0时,输出为1;其余情况输出为0。其布尔表达式为
s = ~(a+b)。
异或门(XOR):另一个著名的门电路:
- XOR门根据输入不同产生不同的输出:当一个输入为1,另一个为0时,输出为1。因此,XOR门在两个输入不同时产生1。其布尔表达式为
s = a ⊕ b,可以使用NOT门、AND门和OR门来表达。
专有名词:
- 以下几个分类的词汇可以互换使用:
- 组合电路(combinational circuits)
- 布尔表达式(Boolean expressions)
- 布尔电路(Boolean circuits)
- 门(gate)、布尔运算符(Boolean operator)
- 在组合电路中,变量用于命名电路中的导线。
真值表
任何组合电路的功能都可以使用真值表来定义。真值表列出了输入的所有可能组合,并为每种输入组合指定了输出。
例如,电路 f 的输入为 a、b、c,输出为 s1 和 s2 的真值表如下所示:
a b c | s1 s2
-------------
0 0 0 | 1 0
0 0 1 | 0 0
0 1 0 | 0 0
0 1 1 | 0 1
1 0 0 | 1 1
1 0 1 | 1 0
1 1 0 | 0 1
1 1 1 | 0 0
对于 n 个输入和 m 个输出的函数,真值表的大小是 ( 2^n ) 个 m 位的行。然而,真值表不适合描述具有大量输入的函数,因为行数会随着输入数量的增加而呈指数增长。
从真值表到布尔表达式
每个真值表都对应一个布尔表达式:
- 对每个输出为1的行,只使用AND和NOT写一个乘积项。
- 最终的布尔表达式是所有这些乘积项的和。
对于上述真值表,s1 和 s2 的布尔表达式可以表示为:
- \( s1 = (\neg a \cdot \neg b \cdot \neg c) + (a \cdot \neg b \cdot \neg c) + (a \cdot \neg b \cdot c) \)
- \( s2 = (\neg a \cdot b \cdot c) + (a \cdot \neg b \cdot \neg c) + (a \cdot b \cdot \neg c) \)
这种表示方式称为乘积之和(SOP)表示。
这些公式的意义在于通过布尔代数的基本运算,我们可以从基本的真值表达到任何特定逻辑功能的表达,它是构建复杂电路设计的基石。通过这种方法,可以将抽象的逻辑设计转化为具体的电路设计。在实际电路设计中,特别是在硬件描述语言(HDL)中,SOP表示形式常用于自动合成电路,并作为优化逻辑的起点。
通用门集
一组逻辑门如果能够用来描述任何布尔函数,则称为通用的。以下是一些例子:
- {AND, OR, NOT}
- {NAND}
- {NOR}
证明:任何真值表都可以用乘积之和的形式表示。
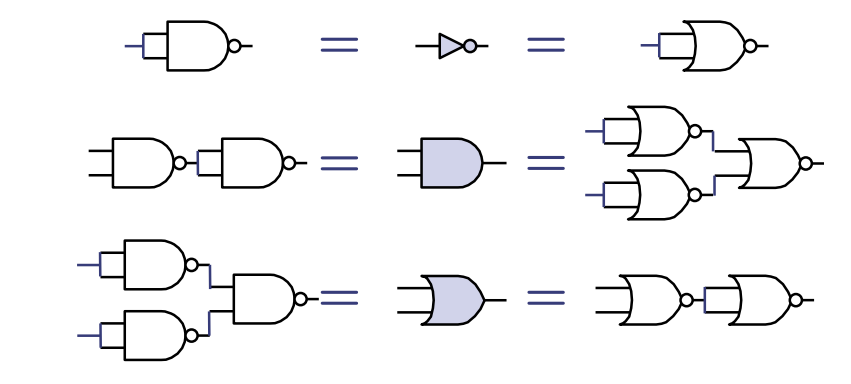
图解证明
图中展示了如何仅使用NAND或NOR门来构建与门、或门和非门的等效电路,证明了NAND和NOR门作为通用门的能力。
二进制加法
二进制加法的执行过程与十进制加法类似。
十进制例子
14加7等于21,在二进制下,1110(即十进制下的14)加111(即十进制下的7)等于10101(即十进制下的21)。
让我们构建一个硬件加法器。
半加器
半加器(HA)可以将两个一位数相加,并产生一个和位和一个进位位。
布尔方程式
- 和位 ( s ) 是输入 ( a ) 和 ( b ) 的异或:\( s = \neg a \cdot b + a \cdot \neg b = a \oplus b \)
- 进位位 ( c ) 是输入 ( a ) 和 ( b ) 的与:\( c = a \cdot b \)
在这段内容中,半加器是基础数字电路设计的初步,通常作为更复杂加法器(如全加器)的基本组件。该布尔方程式表明,半加器可以通过简单的逻辑门操作来实现,其中和位是由两个输入异或(互斥或)得出的结果,而进位位则是由两个输入相与得出的结果。这种设计允许我们在构建数字系统时进行模块化设计,使得可以用相同的半加器模块组合出不同的、更复杂的数字电路。
组合逻辑用于加法器
全加器(FA)将两个一位数和一个进位位相加,并产生一个和位和一个进位位;可以用两个半加器(HA)来构建。
- 为了进行二进制加法,可以级联多个全加器。
描述一个32位加法器的替代方法
- 一个真值表有2^64行和33列(sum(32) + carry(1))。
- 有32组布尔方程组,每组描述一个全加器(FA)。
- 一些表示法用于描述递归:
- \( t_k = a_k \oplus b_k \)
- \( s_k = t_k \oplus c_k \)
- \( c_{k+1} = a_k \cdot b_k + c_k \cdot t_k \) , 0 ≤ k ≤ 31
- 电路图绘制起来繁琐且不直观。
使用名为Bluespec System Verilog(BSV)的编程语言来表达所有电路,因为它更适合计算机模拟电路的行为,即确定给定输入的输出。
在这部分内容中,全加器是通过两个半加器的输出——一个是直接的和位输出,另一个是两个输入与运算的结果,作为进位输出——来构建的。通过级联全加器,我们可以实现任意长度的二进制加法。级联全加器是在数字电路设计中常用的技术,允许一位一位地累加并传递进位。
在描述32位加法器时,真值表方法会变得不可行,因为这会涉及到巨量的数据行和列。这就需要一种更高效的方法来描述加法器的行为,而且能够让计算机轻松处理和模拟。在硬件设计领域,通常会使用硬件描述语言(HDL),如Bluespec System Verilog(BSV),它允许设计师以高级语言的形式来描述硬件逻辑,而后自动转换成电路设计。
上述的递归关系公式是布尔代数中的基本运算,反映了二进制加法中的进位传递逻辑。在这里,⊕ 表示异或运算,是不带进位的加法,而 ⋅ 表示与运算,用于计算进位。Bluespec System Verilog 允许开发者用几乎是编程的形式来设计这样的逻辑,使得可以自动生成和验证硬件电路设计
半加器在Bluespec中的表示
- 展示了在Bluespec中半加器的函数表示和布尔方程式。
- 布尔方程式如下:
- \( s = \neg a \cdot b + a \cdot \neg b = a \oplus b\)
- \( c = a \cdot b\)
- 表示中提到了异或运算
^和与运算&。 - 但代码注明“不太正确 - 需要类型注解”。
半加器修正后的表示
- 补充了类型声明的Bluespec函数定义:
function Bit#(2) ha(Bit#(1) a, Bit#(1) b);
Bit#(1) s; // 声明变量s为一位宽的比特类型
Bit#(1) c; // 声明变量c为一位宽的比特类型
Bit#(2) result; // 声明变量result为两位宽的比特向量
s = a ^ b; // 定义变量s为输入a和b的异或结果,对应 s = a ⊕ b
c = a & b; // 定义变量c为输入a和b的与结果,对应 c = a · b
result[0] = s; // 将s赋值给result的第0位,表示 result 的第0位是和位
result[1] = c; // 将c赋值给result的第1位,表示 result 的第1位是进位位
return result; // 返回result变量
endfunction
- 这个修正版本的函数声明确保了在Bluespec语言中,类型的严格性与硬件设计的准确性密切相关,以确保生成的硬件电路可以正常工作。
这段代码的每一行都是函数定义的一部分,它详细描述了半加器在硬件描述语言Bluespec中的实现。以下是代码的具体解释:
function Bit#(2) ha(Bit#(1) a, Bit#(1) b);- 这行代码声明了一个名为
ha的函数,它返回一个二位宽的比特向量Bit#(2)。这个函数接受两个一位宽的比特参数Bit#(1),分别是a和b。
- 这行代码声明了一个名为
Bit#(1) s;- 这行声明了一个名为
s的变量,它是一个一位宽的比特类型,用于存储半加器的和结果。
- 这行声明了一个名为
Bit#(1) c;- 这行声明了一个名为
c的变量,它也是一个一位宽的比特类型,用于存储半加器的进位结果。
- 这行声明了一个名为
Bit#(2) result;- 这行声明了一个名为
result的二位宽的比特向量,它用于存储函数的最终输出。
- 这行声明了一个名为
s = a ^ b;- 这行代码使用异或运算符
^来计算a和b的和,并将结果赋值给s。在布尔代数中,异或运算符表示两个输入不同则输出为1,相同则为0。
- 这行代码使用异或运算符
c = a & b;- 这行代码使用与运算符
&来计算a和b的进位,并将结果赋值给c。在布尔代数中,与运算符表示只有当两个输入都为1时,输出才为1。
- 这行代码使用与运算符
result[0] = s;- 这行代码将
s赋值给result向量的第0位。
- 这行代码将
result[1] = c;- 这行代码将
c赋值给result向量的第1位。
- 这行代码将
return result;- 这行代码返回
result变量,它包含了半加器的计算结果,其中包括和位和进位位。
- 这行代码返回
endfunction- 这行代码标志着函数定义的结束。
在Bluespec中,类型注释非常重要,因为它们定义了电路中每个信号的宽度,确保在实际硬件实现时能正确地处理信号。函数ha在这里描述的是一个半加器,半加器是数字电路设计中的基础元件,通常用作构建更复杂电路如全加器的基础模块。
更便捷的语法
function Bit#(2) ha(Bit#(1) a, Bit#(1) b);
Bit#(1) s = a ^ b; // 变量类型可以在声明变量的同时定义
Bit#(1) c = a & b; // {…} 可用于定义一个位向量
return {c, s}; // 使用 {c, s} 的表示法避免了命名中间结果的需求
endfunction
- 这个函数
ha返回一个两位宽的位向量,其中包含了和位(s)和进位(c)。 {c, s}的位宽是2位。- 使用
{c, s}这种表示法可以避免对中间结果进行命名,使得代码更加简洁和易于理解。
全加器使用半加器
全加器fa
全加器可以通过两个半加器来构建,并且可以通过级联多个全加器来进行二进制加法运算。
function Bit#(2) fa(Bit#(1) a, Bit#(1) b, Bit#(1) c_in);
Bit#(2) ab = ha(a, b); // 使用半加器计算a和b的和
Bit#(2) abc = ha(ab[0], c_in); // 使用半加器计算上一步的结果和进位位的和
Bit#(1) c_out = ab[1] | abc[1]; // 计算最终的进位位
return {c_out, abc[0]}; // 返回最终的和位和进位位
endfunction
- 这个函数
fa返回一个两位宽的位向量,其中包含了和位(abc[0])和进位(c_out)。 - 半加器在这里被用作黑盒,
fa的代码实际上就是一个连接图。 - 这种设计模式展示了在硬件描述语言中,函数可以被视作黑盒子来使用,通过连接它们的输出输入来构建更复杂的功能模块。
两位的级联进位加法器
二进制级联进位加法器通过级联全加器构建。
function Bit#(3) add2(Bit#(2) x, Bit#(2) y);
Bit#(2) s = 2'b00; // s是一个两位宽的位向量,初始化为0
Bit#(3) c = 3'b000; // c是一个三位宽的位向量,初始化为0
Bit#(2) cs0 = fa(x[0], y[0], c[0]); // 使用全加器计算最低位
s[0] = cs0[0]; // 更新和位的最低位
c[1] = cs0[1]; // 更新进位位
Bit#(2) cs1 = fa(x[1], y[1], c[1]); // 使用全加器计算第二位
s[1] = cs1[0]; // 更新和位的第二位
c[2] = cs1[1]; // 更新进位位
return {c[2], s}; // 返回总和和进位位
endfunction
- 这个函数
add2返回一个三位宽的位向量,其中包含了两个输入x和y的和,以及产生的进位。 - 全加器
fa作为黑盒子被用于计算每一位的和与进位。 - 这段代码展示了二进制加法中级联全加器的基本概念,即如何一步一步地处理每个比特位,同时管理和传递进位。
在上述Bluespec代码中,我们看到了如何利用更简洁的语法来减少代码的冗长性,以及如何将基础的数字逻辑组件如半加器和全加器组合成完成更高级任务的电路。
选择器和多路复用器
选择一个线:x[i]
假设x是4位宽。
-
常数选择器:例如,x[2]
- 这里x[2]表示直接选择x中的第二位。在这个上下文中,没有额外的硬件被使用;x[2]仅仅是一根导线的名字。
-
动态选择器:x[i]
- 与常数选择器不同,动态选择器使用索引i来选择x中的位。这需要一个4路多路复用器,根据i的值动态地选择x[0]、x[1]、x[2]或x[3]。
2路多路复用器
- 一个多路复用器是一个简单的条件表达式。
Bluespec
(p) ? b : a;
在Bluespec语言中,(p) ? b : a;表示如果p为真,则选择b;否则选择a。布尔值真在这里被视为1,假被视为0。
Python
return b if p else a
在Python语言中,return b if p else a与Bluespec中的表达方式类似,也是根据条件p来选择返回b或a。
- 门级实现
- 如果a和b是n位宽,则这个结构将在n次中复制;p是所有复制结构的相同输入。
4路多路复用器
四路多路复用器可以基于两个选择信号从四个输入中选择一个。
语法:
使用Bluespec语言的case语句来实现多路复用器的行为:
case ({s1, s0})
2'b00: a;
2'b01: b;
2'b10: c;
2'b11: d;
endcase
在这里,{s1, s0}是一个2位的选择信号,2'b00,2'b01,2'b10和2'b11代表不同的选择组合。a,b,c和d是四个输入信号。这种语法表明,根据选择信号的值,多路复用器会选择相应的输入信号进行输出。
Python 代码示例:
def mux(a, b, c, d, s):
if s == 0:
return a
elif s == 1:
return b
elif s == 2:
return c
else:
return d
这段Python代码说明了相同逻辑的实现方式:根据选择信号s的值(0, 1, 2, 或 3),函数将返回相应的输入信号(a,b,c,或 d)。
注意,{s1=0} & {s0=1},即选择信号为01时,多路复用器输出b,这与case语句中的2'b01: b;相同。
在n路多路复用器中,通常可以通过组合多个两路多路复用器来实现。例如,一个4路多路复用器可以通过组合三个两路多路复用器来构造。
下一讲
- 更多简单的组合电路
- 逻辑综合和电路优化
课后作业
- 提供一个全加器的真值表。
- 为全加器的每个输出指定一个乘积之和(SOP)表示形式。
多路复用器在数字逻辑中扮演着重要角色,它允许在给定的多个输入信号中基于控制信号选择一个信号。这是逻辑设计中基本的决策组件,广泛用于CPU设计中的寄存器文件、算术逻辑单元(ALU)、和数据路径等场景。在硬件描述语言中,多路复用器通常用条件表达式来描述,这体现了硬件设计中逻辑与编程之间的类似性。
L06-Barrel Shifter, Boolean Optimizations, and Logic Synthesis
MIT 6.004 2019 L06 Barrel Shifter, Boolean Optimizations, and Logic Synthesis,由Silvina Hanono Wachman讲述。
这次讲座的主题为:组合电路和多路复用器的硬件实现。
主要内容
-
组合电路硬件实现:
- 继续上次讨论的内容,深入了解不同组合电路的硬件实现。
- 介绍了半加器、全加器以及不同尺寸的多路复用器的实现细节。
-
移位器的硬件实现:
- 讨论了如何在硬件中实现逻辑和算术移位操作。
- 介绍了实现可变大小移位(0到31位)的硬件设计,以及如何通过多步移位来实现。
-
布尔优化:
- 探讨了如何使用真值表和"不关心"的值来简化电路表示。
- 介绍了通过布尔优化减少和简化门数量的方法。
-
逻辑合成:
- 强调了将高级描述的组合电路转换为硬件电路的重要性,以及这一过程中需要考虑的参数,如门延迟、面积和功耗。
- 讲述了如何使用逻辑合成工具根据特定的门库和优化目标自动化电路设计。
-
课后作业:
- 要求提供一个全加器的真值表。
- 要求为全加器的每个输出指定乘积之和(SOP)表示形式。
讲座最后,教授指出在设计硬件电路时需要理解如加法器和多路复用器等基本组件的功能。通过布尔优化和逻辑合成,设计者能够根据面积、速度和功耗等约束条件制定最优的硬件实现方案。
分页知识点
Shift operators 移位运算符
逻辑右移两位
逻辑右移是一种简单的硬件操作,其中输入的线路会被重新连接到输出的不同位置上。例如,四位数a b c d向右逻辑移动两位,结果是0 0 a b,而最高的两位(c和d)被移出。这种固定大小的移位操作在硬件中很容易实现,并且算术移位与之类似。
- 示例1:
1001向右逻辑移动两位,变为0010。 - 示例2:使用两位补码
1100表示的-4,如果进行算术右移两位(保留符号位),结果是1110,表示的是-2。
逻辑右移n位
如果需要构建一个可以将数值x进行0至31位任意数目的右移的移位器,一种方法是连接32个不同的移位器,并通过一个多路选择器(MUX)来选择输出。
- 例如,要实现从0到31的任意位数移动的移位器,可以用一个大型多路选择器连接32个固定移位器。
但是这种结构需要很多二路一位MUX来实现,具体数量是n*(n-1)。考虑到这样的电路可能非常大,设计者可能会寻求更优的解决方案。
通过n逻辑右移位
逻辑右移可以通过多个步骤实现,每个步骤移动固定长度,比如1、2、4等双倍增加的位数。
- 例如,可以通过先右移4位,然后再移动1位来实现向右移动5位。
- 对于32位数字,一个5位的
n可以指定所有需要的移位,比如n的二进制表示为00101,表示我们需要右移1位和4位。 - 如果
n的最低位(最不重要的位)是1,则我们需要向右移动2^0位。
这是一个权衡延迟和尺寸的例子,其中通过增加多个步骤来减小电路的整体大小。
在硬件设计中,这些移位运算是实现快速算术计算的基础,特别是在处理乘法和除法时,移位操作可以提供有效的计算捷径。例如,在处理器设计中,对寄存器内容的移位操作可以快速实现乘以或除以2的幂等计算。设计者需要在硬件资源消耗(如面积和电力)与计算速度之间进行权衡,找到最适合其应用的解决方案。
条件操作:移位与不移位
我们需要一个多路选择器(MUX)来选择适当的线路:如果s为1,MUX将选择左侧的线路(移位);否则它将选择右侧的线路(不移位)。
- 表达式
(s==1)? {2'b0,a,b}:{a,b,c,d}的意思是,如果s为1,输出为00ab,表示执行移位操作;如果s为0,输出为abcd,表示不执行移位操作。
逻辑右移电路
定义log n个不同大小的移位器,比如1、2、4等。
定义log n个多路选择器来执行特定大小的移位操作。
假设s = {s1,s0}是一个两位的数字。移位电路通过s来移动数字可以通过两个条件表达式表示,其中第二个表达式使用第一个的输出。
- 示例中的代码展示了如何利用Bluespec语言进行逻辑右移操作的描述。
Bit#(4) input = {a,b,c,d}
Bit#(4) tmp = (s1==1)? {2'b0,a,b}:input;
Bit#(4) output = (s0==1)? {1'b0, tmp[3], tmp[2], tmp[1]}:tmp;
{2'b0,a,b}表示将输入a和b移位了两位,最高的两位补0。{1'b0,tmp[3],tmp[2],tmp[1]}则表示将临时变量tmp的最高三位向右移动一位,并在最高位补0。
在硬件设计中,条件移位操作允许根据输入信号s的值决定是否执行移位,这是数据处理和信号处理中的一种常见技术。在处理器中,这种操作通常是用硬件逻辑电路实现的,可以非常快速地进行。逻辑右移电路可以根据需要进行灵活的位移操作,对于实现各种算术运算、数据加工和信号调制非常重要。通过合理设计,这种电路不仅能够确保正确性,还能优化执行速度和硬件资源使用。
Boolean Optimizations 布尔优化
等价性和正规形式
- 每个函数都可以用真值表来描述。
- 每个真值表都对应一个布尔表达式。
例如,以下真值表
| C | B | A | Y |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
的积之和(SOP)形式表示为:
\[Y = \overline{C}\overline{B}A + \overline{C}BA + C B \overline{A} + CBA \]
这种表示称为函数的正规形式(normal form),它是唯一的,但可能存在更简单的表达式。
使用布尔代数简化布尔表达式
可以通过以下布尔代数的性质来操纵布尔表达式:
- 交换律:\( a \cdot b = b \cdot a \),\( a + b = b + a \)
- 结合律:\( a \cdot (b \cdot c) = (a \cdot b) \cdot c \),\( a + (b + c) = (a + b) + c \)
- 分配律:\( a \cdot (b + c) = a \cdot b + a \cdot c \),\( a + b \cdot c = (a + b) \cdot (a + c) \)
- 补码:\( a \cdot \overline{a} = 0 \),\( a + \overline{a} = 1 \)
- 吸收律:\( a \cdot (a + b) = a \),\( a + a \cdot b = a \)
- 约简:\( a \cdot b + a \cdot \overline{b} = a \),\( (a + b) \cdot (a + \overline{b}) = a \)
- DeMorgan 定律:\( \overline{a \cdot b} = \overline{a} + \overline{b} \),\( \overline{a + b} = \overline{a} \cdot \overline{b} \)
利用这些性质,可以从正规形式中去除我们不关心的变量,或者当我们知道一个输入为零时,可以消除那些项。例如,如果我们有一个乘积项 \( a \cdot \overline{a} \),我们知道这不可能为真,因此可以用零替换该乘积项,并从表达式中移除。同样地,如果我们有 \( a + \overline{a} \),我们知道这等同于一,因此是优化的又一个机会。通过这种方式,我们可以将复杂的布尔表达式简化为需要更少门数量和可能更小门的简单表达式。这对于减小硬件成本和提高计算效率至关重要。在设计复杂的逻辑电路时,这种优化是一个必不可少的步骤,它不仅可以减少所需的硬件资源,还能改善电路的性能。
SOPs的布尔简化
- 最小积之和(SOPs)是一种积之和表达式,它拥有可能最少的AND和OR运算符数量。这种表达式对硬件资源的需求更小,因为它可以使用更少且更小的逻辑门来实现。
例如前面的原始表达式:
\[Y = \overline{C}\overline{B}A + C B \overline{A} + CBA + \overline{C}BA\]
它包含了四个项。通过观察,我们可以合并中间两项和两边两项,使用的是布尔代数中的吸收律:
- 合并 \(C B \overline{A}\) 和 \(CBA\) 可以得到 \(CB\),因为 \(CBA + CB\overline{A} = CB(A + \overline{A}) = CB\)。
- 合并 \(\overline{C}\overline{B}A\) 和 \(\overline{C}BA\) 可以得到 \(\overline{C}A\),因为 \(\overline{C}BA + \overline{C}\overline{B}A = \overline{C}A(B + \overline{B}) = \overline{C}A\)。
因此,简化后的表达式为:
\[ Y = \overline{C}A + CB \]
- 最小SOPs可以用更少更小的逻辑门来实现。
- 不同于正规形式,它不是唯一的(一个函数可能有多个最小SOPs)。
在计算机硬件设计中,这种布尔表达式的简化对于优化逻辑电路至关重要。通过减少所需的逻辑门数量,可以节省硬件成本,降低能耗,并可能提升电路的运算速度。简化也可以让电路设计更加简洁,更容易理解和维护。此外,简化过程还有助于减少潜在的错误,因为复杂的逻辑表达式更容易出错。在设计高效能的计算机硬件时,工程师会积极寻找能够简化电路设计的各种方法。
使用“不关心”条件的真值表
使用“不关心”(don't care)条件来简化真值表。在布尔逻辑中,“不关心”的条件表示输入的某些组合不影响输出,这允许我们在设计电路时忽略它们。这通常用于简化布尔表达式,优化电路设计。
- 表格中的“X”或“-”表示不关心的条件。这意味着无论该位的值是0还是1,都不会影响输出结果。
- 通过合并具有相同输出值且只在不关心位上有差异的行,可以减少生成布尔表达式时需要的项数。
例如原始的真值表如下所示:
|行号| C B A | Y
---------------
| 1 | 0 0 0 | 0
| 2 | 0 0 1 | 1
| 3 | 0 1 0 | 0
| 4 | 0 1 1 | 1
| 5 | 1 0 0 | 0
| 6 | 1 0 1 | 0
| 7 | 1 1 0 | 1
| 8 | 1 1 1 | 1
在简化的真值表中,我们用 "X" 或 "-" 来表示“不关心”的条件:
|行号| C B A | Y
---------------
| 1 | 0 X 0 | 0
| 2 | 0 X 1 | 1
| 3 | 1 0 X | 0
| 4 | 1 1 X | 1
| 5 | X 0 0 | 0
| 6 | X 1 1 | 1
对此进行分析:
-
原始行 1和3,无论B的值是什么,如果 \(C=A=0\),则Y总是0。因此,可以合并成简化行1。
-
原始行 2和4,当A=1时,无论B的值是什么,如果C=0,则Y总是1。因此,
0 X 1的行可以合并成一个项,即简化行2, \(\overline{C}A\)。这也包括了简化行1的情况。 -
原始行 5和6,无论A的值是什么,如果C=1,B=0,则Y总是0。因此,可以合并成简化行3。
-
原始行 7和8,当C=1时,无论A的值是什么,如果B=1,则Y总是1。因此,
1 1 X的行可以合并成一个项,即简化行4, \(CB\)。这也包括了简化行3的情况。
到了这一步,我们发现已经能覆盖所有Y=1的情况,因此这个表达式已经足够:
\[ Y = \overline{C}A + CB \]
但是幻灯片中出现了额外的 X 0 0 和 X 1 1 的情况,似乎指向了一个 \(BA\) 项。通常,不需要添加这样的项,除非我们有其他的目的,比如想要在实现电路时有更好的性能(例如,减少延迟或简化硬件实现)。在没有这样的需求下,\(BA\) 项是不必要的,因为 \(CB\) 和 \(\overline{C}A\) 已经完整地覆盖了所有Y=1的情况。
在实际的逻辑电路设计中,可能会有其他考虑,比如确保电路的对称性或制造工艺的要求,这些都可能导致在简化的真值表中添加额外的项。在没有特定背景知识的情况下,我们只能根据布尔逻辑的简化规则进行分析。
多级电路
如果我们只能使用双输入的AND和OR门,则乘积之和(Sum-of-Product, SOP)电路不总能仅使用两级逻辑来实现。例如:
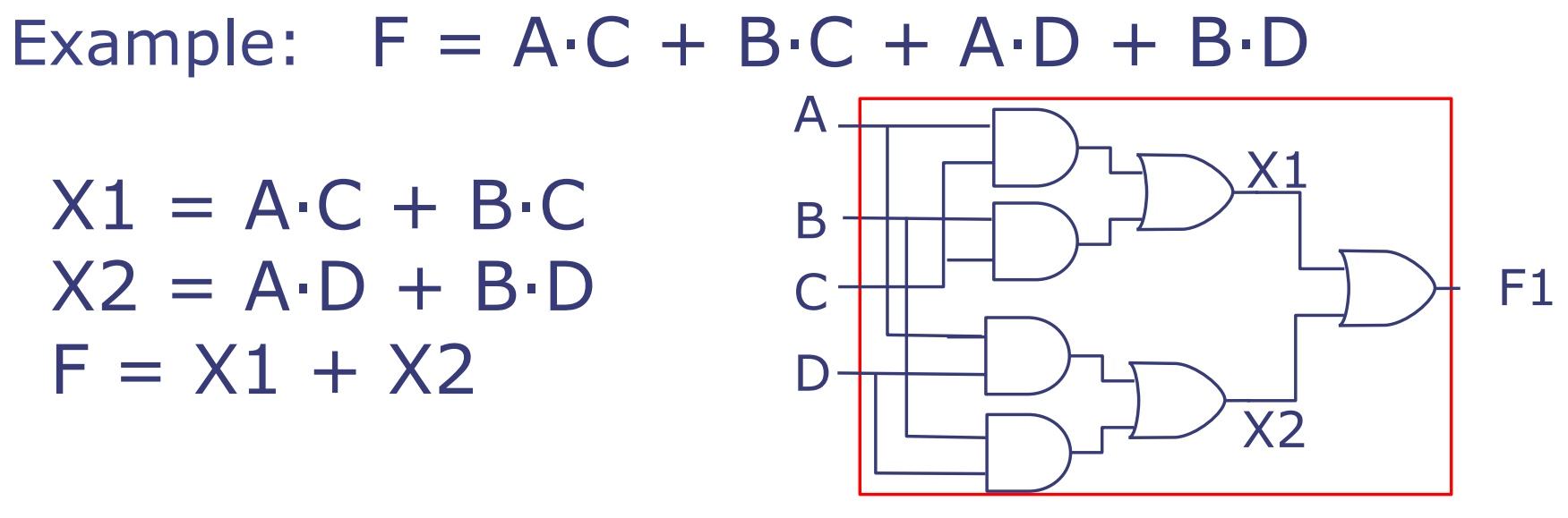
函数F可以表达为A与C的AND(A·C),B与C的AND(B·C),A与D的AND(A·D),以及B与D的AND(B·D)的OR组合。即:
\[ F = A·C + B·C + A·D + B·D \]
为了适应仅有双输入门的限制,我们可以将F分解为两个中间变量X1和X2:
\[ X1 = A·C + B·C \] \[ X2 = A·D + B·D \]
然后F是X1和X2的OR结果:
\[ F = X1 + X2 \]
在快速的微处理器中,通常会使用8级逻辑电路,而较慢的处理器可能会使用14到18级的逻辑电路。
这种多级逻辑设计允许设计者创建复杂的电路,即使在受限于门输入数量的情况下。在这个例子中,为了实现函数F,我们需要组合多个逻辑门而不是使用单个门,这可能会导致电路延迟的增加,但允许我们在受限硬件中实现复杂功能。快速处理器使用更多级别的逻辑,以便优化它们的性能,尽管这可能会导致每个操作的完成需要更多时间。而慢速处理器使用更多级别的逻辑是因为它们可能在设计时考虑了更多的节能和成本效益因素。在微处理器设计中,逻辑级别的数量和电路的速度、能效之间需要权衡。
公共子表达式优化(CSE)
我们常常可以通过提取公共子表达式来减少逻辑门的数量。
例如:函数F可以表示为A与C的AND操作(A·C),B与C的AND操作(B·C),A与D的AND操作(A·D)以及B与D的AND操作(B·D)的OR组合,这是最小的乘积之和形式(minimal SOP)。
\[ F = A·C + B·C + A·D + B·D \]
通过提取公共项A+B,F可以重写为:
\[ F = (A+B)·C + (A+B)·D \]
然后通过引入一个新的中间变量X代表A+B,F可进一步简化为:
\[ X = A + B \] \[ F = X·C + X·D \]
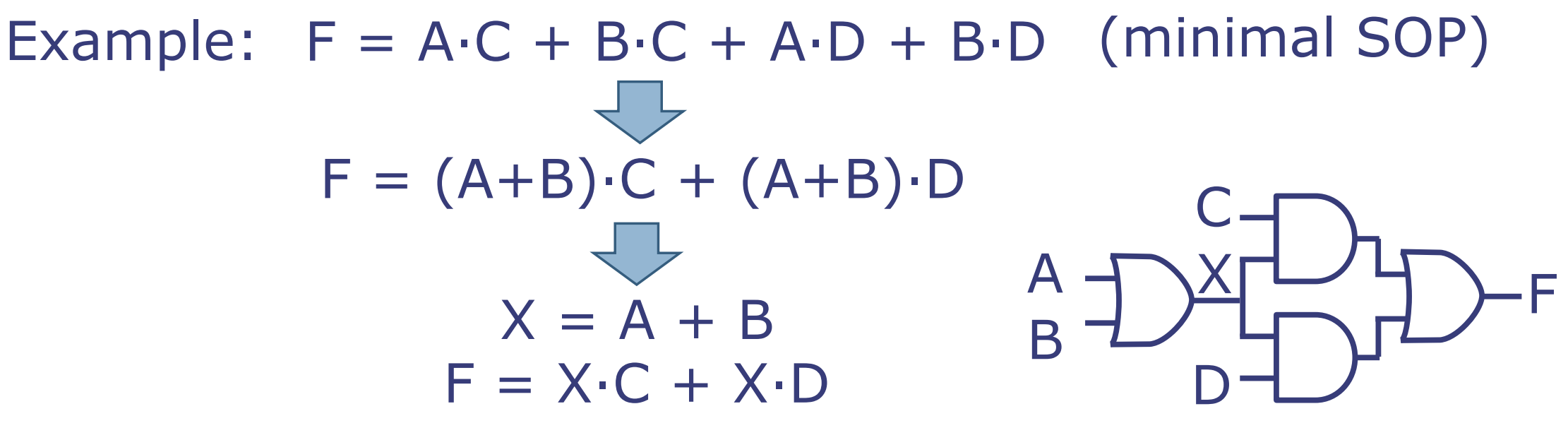
CSE优化可能会增加逻辑级别的数量。到目前为止,我们合成的电路总是看起来像是一个树结构,但是CSE优化的引入可以将树转换为一个有向无环图(DAG)。
多级简化没有明确定义的最优解,这意味着在寻求逻辑电路简化时,可能会有多种方法和结果,取决于优化的目标是减少门数量、减少逻辑级别,还是其他因素。这种优化可以提高电路的效率,但可能也会增加电路的复杂性。在逻辑电路设计中,找到最优的设计通常涉及到多方面的权衡,包括计算速度、硬件成本、能耗和物理尺寸等。
Logic Synthesis 逻辑综合
组合电路属性
- 除了它们的功能性,组合电路还具有两个重要的物理属性:面积(area)和传播延迟(\(t_{pd}\)),即输出稳定化所需的时间。
- 这两个属性都是基于构建电路所用门的特性。
- 大部分电路都是基于特定CMOS技术实现的标准单元库构建的。
在设计组合电路时,功能性不是唯一的考量。电路的物理属性,例如占用的面积和信号在电路中传播所需的时间(即传播延迟),同样非常重要。面积直接关系到芯片的成本和制造复杂性,而传播延迟则影响电路的速度和响应时间。
计算面积和传播延迟
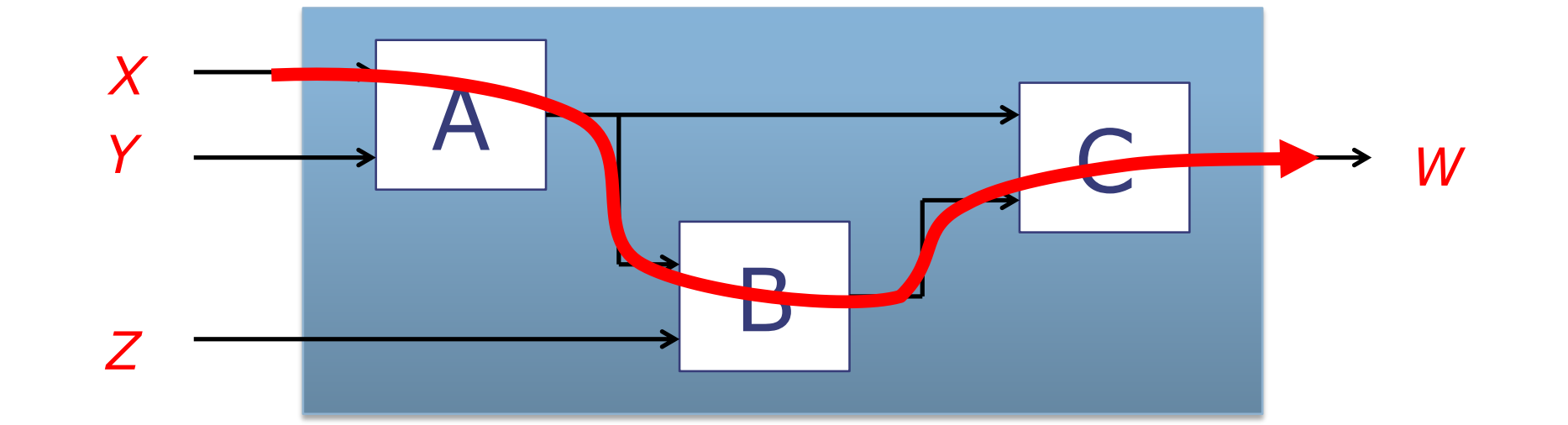
- A、B和C是组合电路。
- 输入为X、Y和Z,经过组合电路,输出为W。
- 功能描述:
- \( W = f_{C}(f_{A}(X, Y), f_{B}(f_{A}(X, Y), Z)) \)
- 这个表达式描述了输出W是如何从输入X、Y、Z和内部组合电路A、B、C得到的。它说明电路C的输出W是由电路A处理输入X和Y的结果,以及电路B处理电路A的输出和输入Z的结果,这两个结果共同决定的。
- 传播延迟:
- \( t_{pd} = t_{pd,A} + t_{pd,B} + t_{pd,C} \)
- 这个公式计算了电路的总传播延迟,它是电路A、B和C各自传播延迟的总和。传播延迟是指从输入信号稳定到输出信号稳定所需的时间。这里假设信号从电路A流向B,再流向C,因此这三个电路的延迟是连续的,它们的延迟会累加。
- 面积:
- \( \text{area} = \text{area}_A + \text{area}_B + \text{area}_C \),忽略了连线的面积。
- 这个公式计算了整个组合电路的总面积,它是构成电路A、B和C各自面积的总和。面积是指电路所占用的物理空间大小,与电路的复杂度和成本直接相关。这里忽略了电路之间连线的面积,这在小电路中是常见的做法,但在更大或更复杂的设计中,连线可能占据显著的面积并影响总面积。
这些物理属性来自于构建电路的基本组件——逻辑门(比如AND门、OR门等)的性能。例如,较小的门可能会占用更少的面积,但可能导致更长的传播延迟。设计师通常需要在这些不同的性能指标之间权衡,以优化整个电路的性能和成本。
在计算一个由多个组合电路构成的复杂电路的面积和传播延迟时,我们需要考虑每个子电路的对应属性。通常,电路的总传播延迟是沿最长路径的延迟之和,而总面积是各个子电路面积的总和(忽略连线的面积)。在实践中,设计工具会考虑这些参数来帮助设计师选择合适的门,以达到设计目标。
标准单元库
标准单元库是一系列集成电路门的集合,这些门具有特定的物理特性,例如延迟和面积。以下是一些常见的门和它们的特性:
| 门类型 | 延迟 (ps) | 面积 (μ²) |
|---|---|---|
| 反相器 (INV) | 20 | 10 |
| 二输入与门 (AND2) | 50 | 25 |
| 二输入与非门 (NAND2) | 30 | 15 |
| 二输入或门 (OR2) | 55 | 26 |
| 二输入或非门 (NOR2) | 35 | 16 |
| 四输入与门 (AND4) | 90 | 40 |
| 四输入与非门 (NAND4) | 70 | 30 |
| 四输入或门 (OR4) | 100 | 42 |
| 四输入或非门 (NOR4) | 80 | 32 |
观察结果
- 在当前CMOS技术中,反向门(如反相器、与非门和或非门)通常比正向门(如与门和或门)更快且更小。
- 随着输入数的增加,延迟和面积也会增加。这表示多输入的门(如四输入门)相比较于少输入的门(如二输入门),其延迟更长,面积更大。
电路设计师在设计电路时,会根据所需的功能、延迟和面积要求,以及电路的功耗限制,从标准单元库中选择合适的门来构建电路。在选择门时,需要综合考虑这些因素,以实现电路设计的最优化。例如,如果面积是一个关键限制因素,那么设计师可能会倾向于选择尺寸更小的门;如果性能是主要考虑,那么可能会选择延迟更低的门。在CMOS技术中,由于反向门具有更好的性能特点,因此在实际电路设计中它们被广泛使用。
设计权衡:延迟与尺寸
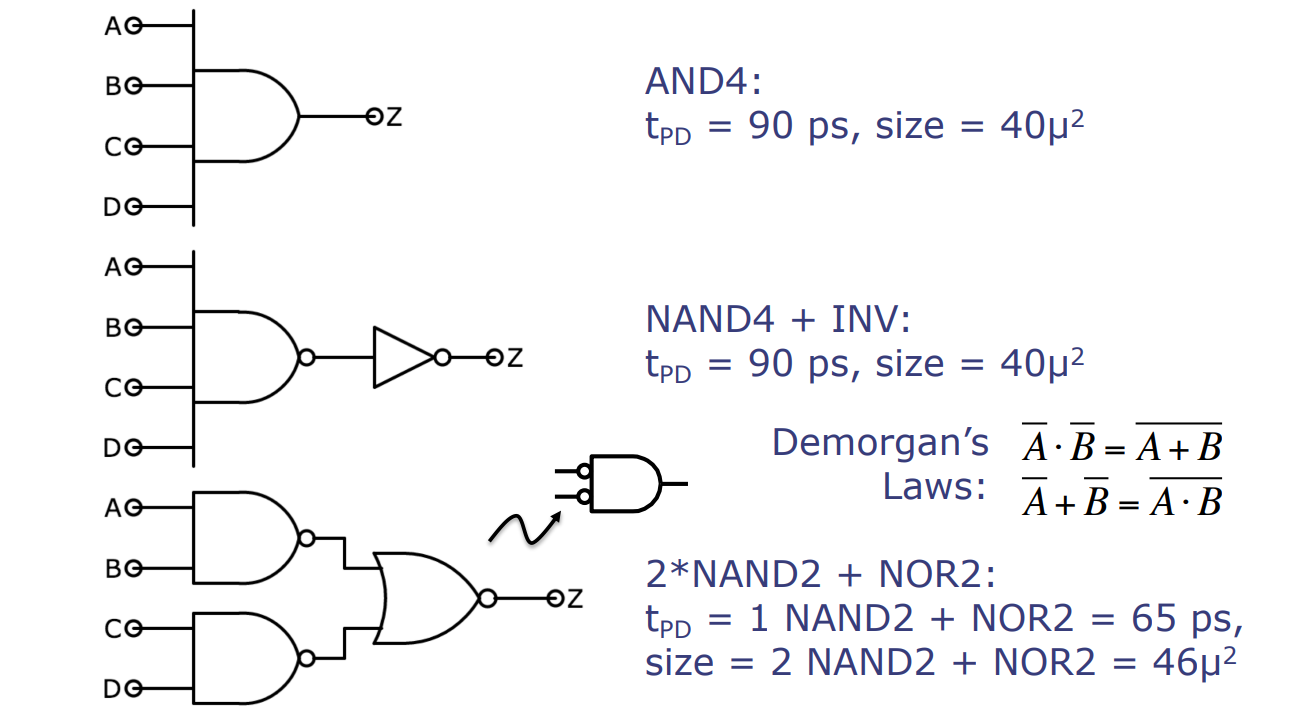
此图展示了在电路设计中考虑延迟和尺寸时可能面临的权衡。
-
四输入与门(AND4):延迟为90皮秒,面积为40微米平方。
-
四输入与非门加反相器(NAND4 + INV):延迟为90皮秒,面积为40微米平方。
-
使用德摩根定律将与门转换为与非门和反相器
- DeMorgan 定律:\( \overline{a \cdot b} = \overline{a} + \overline{b} \),\( \overline{a + b} = \overline{a} \cdot \overline{b} \)
-
两个二输入与非门加一个二输入或非门(2*NAND2 + NOR2):延迟为65皮秒,面积为46微米平方。
详细解释
- 直接使用四输入与门的方案最简单,但如果需要更小的延迟,可能不是最优的选择。
- NAND加反相器的方案通过使用与非门和反相器(遵循德摩根定律)来实现与门的功能,具有与直接使用与门相同的延迟和尺寸。
- 两个NAND加一个NOR的方案利用了两个二输入与非门来分别处理输入的一部分,并使用二输入或非门来整合结果。通过这种方式,尽管增加了面积,但显著减少了延迟。这展示了设计者如何在构建逻辑电路时,在不同的物理特性之间进行权衡。
在现实世界的硬件设计中,选择使用哪种门结构常常取决于特定应用对延迟和尺寸的具体要求。例如,如果设计要求低延迟,即使面积较大,设计者也可能选择使用多个与非门和或非门组合的方案。这种设计的复杂性体现了现代集成电路设计中必须考虑的多个维度。
三种逻辑门的配置方式和它们各自的真值表
为了解释这三种逻辑门的配置方式和它们各自的真值表,我们首先要明确四个输入的与门(AND4)直接计算所有输入的逻辑与。对于四输入的与非门加反相器(NAND4 + INV)和两个二输入与非门加一个二输入或非门(2*NAND2 + NOR2),它们都是以不同的方式实现相同的四输入与操作。
下面是三种配置方式的流程和它们的真值表:
-
直接使用四输入与门(AND4):
-
流程:所有输入直接通过一个四输入与门。
-
真值表:
A B C D | AND4 --------------- 0 0 0 0 | 0 0 0 0 1 | 0 ... ... | ... 1 1 1 1 | 1 -
所有可能的输入组合中,只有当所有输入都为1时,输出才为1。
-
-
四输入与非门加反相器(NAND4 + INV):
-
流程:首先输入通过与非门,然后输出经过反相器。
-
真值表(先展示NAND4,然后INV):
A B C D | NAND4 | INV ---------------------- 0 0 0 0 | 1 | 0 0 0 0 1 | 1 | 0 ... ... | ... | ... 1 1 1 1 | 0 | 1 -
NAND4产生与AND4相反的结果,反相器再将其反转,因此最终结果与AND4相同。
-
-
两个二输入与非门加一个二输入或非门(2*NAND2 + NOR2):
-
流程:两个NAND2分别处理输入对AB和CD,然后NOR2将这两个结果结合,再通过一个与非门实现逻辑与操作。
-
真值表(展示两个NAND2,然后对两个NAND2的结果NOR2):
A B | NAND2 | C D | NAND2 | NOR2 | ---------------------------------- 0 0 | 1 | 0 0 | 1 | 0 | 0 0 | 1 | 0 1 | 1 | 0 | 0 0 | 1 | 1 0 | 1 | 0 | 0 0 | 1 | 1 1 | 0 | 0 | 0 1 | 1 | 0 0 | 1 | 0 | 0 1 | 1 | 0 1 | 1 | 0 | 0 1 | 1 | 1 0 | 1 | 0 | 0 1 | 1 | 1 1 | 0 | 0 | 1 0 | 1 | 0 0 | 1 | 0 | 1 0 | 1 | 0 1 | 1 | 0 | 1 0 | 1 | 1 0 | 1 | 0 | 1 0 | 1 | 1 1 | 0 | 0 | 1 1 | 0 | 0 0 | 1 | 0 | 1 1 | 0 | 0 1 | 1 | 0 | 1 1 | 0 | 1 0 | 1 | 0 | 1 1 | 0 | 1 1 | 0 | 1 | -
通过这种方法,当所有输入都为1时,最终的输出为1,与AND4一致。
-
例子:电路映射到标准单元库
图中的电路由若干个逻辑门组成,它们的物理特性,如面积,是以某个标准单元库中的元素为基准的。这个库给出了不同类型门的面积,例如,反相器面积为2,两输入与非门面积为3,两输入或非门面积为4,两输入或门面积为5。
在设计电路时,工程师会基于特定的目标进行优化。例如,可以是最小化面积,这意味着在满足电路功能需求的同时,尽可能使用面积小的逻辑门。在这个过程中,设计者可能会选择一些逻辑上等效,但在物理特性上差异显著的组件,以达到其优化目标。
例如,如果要最小化面积,我们可能会选择使用面积为3的两输入与非门,而不是面积为5的两输入或门,即使它们在逻辑功能上可以互换。然而,这样的决策必须考虑到电路的整体性能,因为选择较小面积的门可能会对电路的速度和功耗产生影响。
这个过程需要工程师深入理解门的物理特性和逻辑功能,以及它们如何影响电路的整体设计。
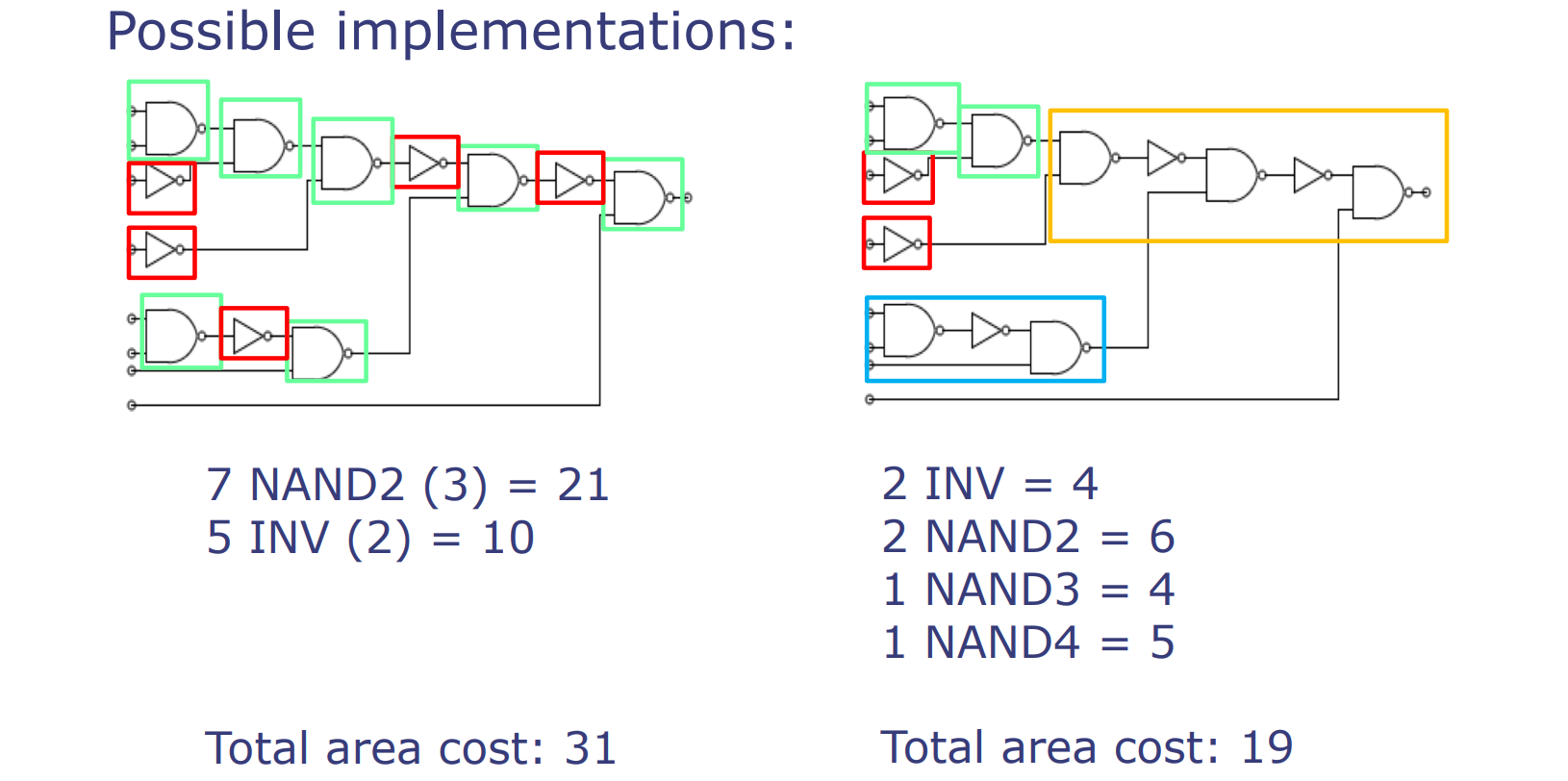
图中展示了一个电路映射到标准单元库的两种可能实现方式。
第一种实现使用了7个两输入与非门(NAND2),每个面积为3,以及5个反相器(INV),每个面积为2,总面积成本为31。在这种布局中,所有逻辑操作都是直接通过与非门和反相器实现的,没有利用更高输入数量的门。
第二种实现更为精巧,它使用了不同类型和不同输入数量的门:2个反相器,每个面积为2,2个两输入与非门,每个面积为3,一个三输入与非门(面积为4),以及一个四输入与非门(面积为5),总面积成本为19。这种布局利用了不同的逻辑门组合以降低总面积。
逻辑优化与合成工具是现代计算机硬件设计中至关重要的组成部分。以下是根据你提供的内容,对图中信息的翻译和解释:
逻辑优化
- 优化电路的合成是一个非常复杂的问题,涉及布尔简化、映射到拥有许多门的单元库,以及多维度的折衷(例如,最小化面积-延迟-功耗的乘积)。
- 手动完成除最小型电路之外的所有电路几乎是不可行的。
- 因此,硬件设计师使用硬件描述语言来编写电路,并利用合成工具来推导出优化的实现。
逻辑合成工具
- 在实际中,工具使用布尔简化和其他技术来合成满足特定面积、延迟和功耗目标的电路。工具的输入包括:
- 高级电路规格说明(例如,布尔代数,Bluespec语言)
- 标准单元库(包含一组门及其物理特性)
- 优化目标(面积/延迟/功耗)
- 合成工具的输出是使用标准单元库门实现的优化电路。
这个过程体现了硬件设计中的逻辑优化如何依赖于自动化工具来处理复杂性和实现高效的硬件设计。设计者不再需要手动执行这些优化,而是依赖于先进的合成工具来优化设计,以满足不断增长的性能需求和复杂性管理。合成工具的高级功能包括能够处理复杂的设计参数,自动识别和实施优化策略,以及将设计映射到具有具体物理特性的标准单元库。这种自动化过程不仅加快了设计过程,还提高了设计的质量和效率。
课后作业
-
为以下布尔(SOP)表达式找到一个最小的乘积和(SOP)表达式: \[ \overline{A}BC + A\overline{B}C + A\overline{B}\overline{C} + ABC \]
-
使用幻灯片#18中的门 (见#标准单元库),找到一个实现这个最小SOP的方法,以最小化面积。
下一讲
- Bluespec 中的复杂组合电路
附:基本的逻辑门
-
NOT Gate (非门)
-
符号:\(\overline{A}\)或\(A'\)
-
表达式: 如果输入是\(A\),输出是\(\overline{A}\)。
-
A | NOT A --------- 0 | 1 1 | 0
-
-
AND Gate (与门)
-
符号:\(A \cdot B\)
-
表达式: 如果输入是\(A\) 和\(B\),输出是\(A \cdot B\)。
-
A B | A AND B ----------- 0 0 | 0 0 1 | 0 1 0 | 0 1 1 | 1
-
-
OR Gate (或门)
-
符号:\(A + B\)
-
表达式: 如果输入是\(A\) 和\(B\),输出是\(A + B\)。
-
A B | A OR B ----------- 0 0 | 0 0 1 | 1 1 0 | 1 1 1 | 1
-
-
NAND Gate (与非门)
-
符号:\(\overline{A \cdot B}\)
-
表达式: 如果输入是\(A\) 和\(B\),输出是\(\overline{A \cdot B}\)。
-
A B | A NAND B ------------- 0 0 | 1 0 1 | 1 1 0 | 1 1 1 | 0
-
-
NOR Gate (或非门)
-
符号:\(\overline{A + B}\)
-
表达式: 如果输入是\(A\) 和\(B\),输出是\(\overline{A + B}\)。
-
A B | A NOR B ------------ 0 0 | 1 0 1 | 0 1 0 | 0 1 1 | 0
-
-
XOR Gate (异或门)
-
符号:\(A \oplus B\)
-
表达式: 如果输入是\(A\) 和\(B\),输出是\(A \oplus B\)。这表示当\(A\) 和\(B\) 不相同时输出为真(1)。
-
A B | A XOR B ------------ 0 0 | 0 0 1 | 1 1 0 | 1 1 1 | 0
-
-
XNOR Gate (同或门)
-
符号:\(\overline{A \oplus B}\) 或\(A \equiv B\)
-
表达式: 如果输入是\(A\) 和\(B\),输出是\(\overline{A \oplus B}\)。这表示当\(A\) 和\(B\) 相同时输出为真(1)。
-
A B | A XNOR B ------------- 0 0 | 1 0 1 | 0 1 0 | 0 1 1 | 1
-
附:使用布尔代数简化布尔表达式
- 交换律:\( a \cdot b = b \cdot a \),\( a + b = b + a \)
- 结合律:\( a \cdot (b \cdot c) = (a \cdot b) \cdot c \),\( a + (b + c) = (a + b) + c \)
- 分配律:\( a \cdot (b + c) = a \cdot b + a \cdot c \),\( a + b \cdot c = (a + b) \cdot (a + c) \)
- 补码:\( a \cdot \overline{a} = 0 \),\( a + \overline{a} = 1 \)
- 吸收律:\( a \cdot (a + b) = a \),\( a + a \cdot b = a \)
- 约简:\( a \cdot b + a \cdot \overline{b} = a \),\( (a + b) \cdot (a + \overline{b}) = a \)
- DeMorgan 定律:\( \overline{a \cdot b} = \overline{a} + \overline{b} \),\( \overline{a + b} = \overline{a} \cdot \overline{b} \)
附:异或(XOR)和 同或(XNOR)
异或(XOR)和同或(XNOR)也是基本的布尔运算,它们也遵循一些规律和公式。以下是一些异或(XOR)和同或(XNOR)的常见性质:
异或(XOR)的性质:
-
交换律:
\( A \oplus B = B \oplus A \)
-
结合律:
\( A \oplus (B \oplus C) = (A \oplus B) \oplus C \)
-
恒等律:
\( A \oplus 0 = A \)
\( A \oplus A = 0 \)
-
逆元:
\( A \oplus \neg A = 1 \)
-
自反性:
\( A \oplus A = 0 \)
-
对偶性(配对的异或总是可以简化):
\( A \oplus A \oplus B = B \)
-
消去律:
如果 \( A \oplus B = A \oplus C \) 则 \( B = C \)
-
分配律:
\( A \oplus (B \land C) = (A \oplus B) \land (A \oplus C) \) (注意,异或运算不满足与“与”、“或”运算相同的分配律)
同或(XNOR)的性质:
同或运算通常定义为异或的补码,也就是 \( A \odot B = \neg (A \oplus B) \) 或 \( A \odot B = A \land B + \neg A \land \neg B \)。
-
交换律:
\( A \odot B = B \odot A \)
-
结合律:
\( A \odot (B \odot C) = (A \odot B) \odot C \)
-
恒等律:
\( A \odot 1 = A \)
\( A \odot \neg A = 0 \)
-
逆元:
\( A \odot A = 1 \)
\( A \odot \neg A = 0 \)
-
自反性: 与异或的自反性相反,同或的结果始终为真: \( A \odot A = 1 \)
-
分配律: 与异或类似,同或的分配律也与常规逻辑运算不同:
\( A \odot (B \lor C) = (A \odot B) \lor (A \odot C) \)
异或 和 同或 和 与或非
异或(XOR)操作符经常在等效的布尔表达式中代替一组“与”、“或”、“非”操作,因为它对应于不同输入值下的排他性输出。以下是异或与基本逻辑运算符之间的一些等价公式:
-
异或运算可以表示为与、或和非的组合:
\( A \oplus B = (A \land \neg B) \lor (\neg A \land B) \)
-
异或运算可以用来表示不等性:
\( A \neq B \) 等价于 \( A \oplus B \)
-
同或(XNOR)表示等价性,可以表示为与、或和非的组合:
\( A \odot B = \neg (A \oplus B) \)
\( A \odot B = (A \land B) \lor (\neg A \land \neg B) \)
-
异或与与(AND)的结合关系:
\( (A \oplus B) \land C = (A \land C) \oplus (B \land C) \)
-
异或与或(OR)的关系比较复杂,因为它们没有直接的分配律。但是,你可以用异或表示一个或运算的特定情况:
如果 \( A \land B = 0 \),那么 \( A \oplus B = A \lor B \)
-
异或的否定是同或,相当于相等运算符:
\( \neg (A \oplus B) = A \odot B \)
-
异或也可以用于条件表达式的变形:
\( A \oplus B \) 等价于 \( (A \land \neg B) \lor (\neg A \land B) \)
这意味着 \( A \) 与 \( B \) 一个为真一个为假时结果为真。
在数字逻辑和计算机硬件设计中,这些等价关系可以用于简化逻辑电路,特别是在优化电路复杂度和所需逻辑门数量时非常有用。在某些情况下,直接使用异或门比构建相同功能的“与”、“或”、“非”逻辑门结构更高效。
使用 "+" "·":
-
异或表示为与、或和非的组合:
\( A \oplus B = (A \cdot \overline{B}) + (\overline{A} \cdot B) \)
-
同或(XNOR)表示为与、或和非的组合:
\( A \odot B = \overline{A \oplus B} \)
\( A \odot B = (A \cdot B) + (\overline{A} \cdot \overline{B}) \)
-
异或与与(AND)的结合:
\( (A \oplus B) \cdot C = (A \cdot C) \oplus (B \cdot C) \)
-
当 A 和 B 互斥(即不同时为真)时,异或等价于或:
如果 \( A \cdot B = 0 \),那么 \( A \oplus B = A + B \)
-
异或的否定是同或,表示相等性:
\( \overline{A \oplus B} = A \odot B \)
L07-Complex Combinational Circuits in Bluespec
MIT 6.004 2019 L07 Complex Combinational Circuits in Bluespec,由教授Arvind讲述。
这次讲座的主题为:Bluespec 中的复杂组合电路
主要内容
-
组合电路回顾:在前两次课程中介绍了组合电路,并展示了如何使用Bluespec语言编写一些简单的组合电路。今天,我们将着手解决更复杂的组合电路,并探讨新出现的问题。
-
Bluespec语言的重要性:Bluespec是一种硬件设计语言,通过它,我们可以像绘图一样表达电路,电路由门和连线等元素构成。与普通的绘图程序(如PowerPoint)不同,Bluespec中的盒子(即门)具有明确的计算含义,可以基于输入推断输出。
-
电路仿真的重要性:Bluespec不仅可以设计电路,还可以对电路进行仿真,以验证给定输入下的输出。这是设计前验证电路正确性的关键步骤。
-
Bluespec编译器的功能:Bluespec编译器的主要目的是帮助设计高效的电路,仿真功能是额外的优势。过去,电路设计常常需要手动完成,但现在借助Bluespec,即使是复杂的电路也可以仿真。
-
电路的输入输出行为:在讨论电路的功能时,并非专指电路的实际生成,而是指电路的输入输出行为。
-
32位加法器的例子:通过Bluespec循环结构来展示如何构建32位加法器,这种方法不仅节省了重复代码的工作,而且减少了出错的可能性。
-
类型系统的介绍:Bluespec的类型系统帮助硬件设计师避免错误的连接,提供了强大的参数化功能,可以通过修改参数来轻松改变电路的规模。
-
参数化电路的概念:参数化电路可以根据需要实例化为不同大小的电路,这是硬件设计中的一个高级概念。
-
类型错误和类型推导:Bluespec强类型系统可能在初学者使用时会遇到一些挫折,但一旦熟悉,它可以极大地减少错误,并简化程序的编写。
-
强类型语言的优势:在强类型语言中,每个表达式都有类型,这有助于避免许多错误。例如,使用枚举类型声明可以防止不同类别的值被错误地比较或混淆。
-
使用let语法简化类型声明:Bluespec提供的let语法可以减轻程序员声明类型的负担,允许编译器自动推断表达式的类型。
-
类型推导和类型错误检测:编译器可以检测并指出代码中的类型不一致之处,从而减少编程错误。如果出现类型错误,编译器会拒绝编译并提供错误信息。
-
循环和函数的展开:Bluespec中的循环和函数在编译时会被展开,生成无环的门图,这确保了电路的正确设计。
-
参数化类型的高级概念:参数化类型允许创建具有广泛适用性的电路描述,这些电路可以根据参数变化自由扩展。
-
数字类型的使用:在Bluespec中,可以将数字用作类型,这允许设计者创建更具表现力的类型定义,如将数字用作向量的尺寸或其他类型的参数。
分页知识点
Bluespec 用于描述电路
- Bluespec是用于描述电路的一种语言,就像绘制互连箱的图画一样。
- 这些箱子实际上是带有输入和输出的布尔门。
- 然而,不同于普通图画,我们的箱子,即门,有计算意义,因此我们可以询问,在特定的输入值集上,一个电路将在其输出线上产生什么值。
- 尽管Bluespec编译器的主要目的是合成门网络,但能够模拟结果电路的功能也非常重要。
Bluespec是一个用于描述电路的语言,特别是在布尔逻辑和组合电路的上下文中。它允许设计者以类似于绘图的方式来构建和表示电路,其中每个盒子代表一个布尔门,具有确定的逻辑功能和计算意义。这样的表示法不仅便于理解和设计电路,而且通过Bluespec编译器的合成功能,可以转换为物理硬件门的网络。
此外,Bluespec还具有模拟电路功能的重要性,即在电路设计和验证过程中,设计者可以检查和测试电路在给定特定输入集时的行为,确保设计满足预期的功能和性能规格。这种模拟是验证复杂电路设计正确性的关键步骤,确保在硬件实现之前电路设计没有逻辑错误。
Bluespec:门合成与仿真 - 2位加法器
// 定义一个返回3位宽位向量的函数add2,接受两个2位宽的参数x和y
function Bit#(3) add2(Bit#(2) x, Bit#(2) y);
// 初始化和s和进位c为0
Bit#(2) s = 0; // 和s是一个2位宽的位向量
Bit#(3) c = 0; // 进位c是一个3位宽的位向量,包括最初的进位c[0]
c[0] = 0; // 最低位的进位初始化为0
// 使用全加器fa计算第0位的和与进位
Bit#(2) cs0 = fa(x[0], y[0], c[0]); // cs0包含第0位的和与进位
s[0] = cs0[0]; // 将第0位的和存入s[0]
c[1] = cs0[1]; // 将第0位的进位存入c[1],作为下一位的进位输入
// 使用全加器fa计算第1位的和与进位
Bit#(2) cs1 = fa(x[1], y[1], c[1]); // cs1包含第1位的和与进位
s[1] = cs1[0]; // 将第1位的和存入s[1]
c[2] = cs1[1]; // 将第1位的进位存入c[2],这是最终的进位输出
// 函数返回一个位向量,包含最高的进位和2位宽的和
return {c[2],s}; // 最高位c[2]是整个加法的进位输出,s是两位的和
endfunction
add2(2'b11, 2'b01)=>3'b100// 二进制11(即十进制3)加上01(十进制1)等于100(十进制4)add2(2'b01, 2'b01)=>3'b010// 二进制01(即十进制1)加上01(十进制1)等于010(十进制2)
注意:尽管Bluespec程序可以像其他软件语言那样产生输出,但Bluespec程序的主要目的是为了描述硬件电路。全加器fa
在这个例子中,我们看到了Bluespec语言中函数的声明和位向量的操作。通过Bit#(n)语法,Bluespec能够明确指定变量所能容纳的位宽,这在硬件设计中是基础且必要的。函数add2通过调用全加器fa计算每一位的和与进位,然后将计算结果组合返回。这个过程在硬件设计中是通过门电路实现的,Bluespec提供了一个高级的方法来表达这些门电路,并允许仿真这些电路以验证其行为。
编译Bluespec到电路
在这个过程中,Bluespec设计通过Bluespec编译器编译成独立于技术的门描述。这些描述进一步通过Verilog编译器转换为网表,这些网表是建立在特定技术(例如22nm工艺)的门库上。
静态展开(Static elaboration)
Bluespec编译器消除了所有没有直接硬件意义的构建,例如:
- 所有数据结构都被转换成位向量(bit vectors)。
- 循环(loops)被展开。
- 函数(functions)被内联(in-lined)。
- 最后剩下的是一个布尔门(Boolean gates)的无环图(acyclic graph)。
- 如果编译器在你的电路中检测到一个循环,它会报错。
这个过程确保了Bluespec设计能够有效地转换成硬件实现。例如,在Bluespec中使用的高级数据结构和控制流结构在编译后都会被转换为可以在硬件中实现的形式。这种转换确保了高级抽象在硬件层面得到了正确的表达和实现。而对循环的处理则意味着在硬件设计中避免了潜在的循环依赖,从而确保了生成的硬件电路的正确性和效率。
补充:术语解释
位向量(Bit Vectors)
位向量是一个一维的二进制数字数组,用于表示多个数字或信号的集合。在硬件设计中,它们用于表示寄存器、总线和其他数字信号的值。位向量允许设计者在单个变量中处理多个位,对数字电路进行建模。
循环展开(Loop Unfolding)
在硬件描述语言中,循环展开是将循环结构转换为重复的语句块的过程。由于硬件执行是并行的,不能像软件程序那样实时计算循环,因此必须将循环转换为一系列的硬件实现。循环展开确保每次迭代中使用的硬件资源都被明确定义,从而避免了硬件设计中的动态控制结构。
内联(In-lining)
内联是一种编译时优化技术,它将函数调用替换为函数体本身的过程。在硬件设计中,这意味着用函数体替换每个函数调用,减少了函数调用开销,直接插入函数代码可以减少需要的控制逻辑,减小延迟,并可能降低电路的整体复杂性。
布尔门(Boolean Gates)
布尔门是实现布尔函数的基本硬件设备。例如,与门(AND)、或门(OR)、非门(NOT)等实现了基本的布尔运算。每个布尔门都接受一个或多个二进制输入,产生一个二进制输出。在电路设计中,这些基本单元被组合成复杂的逻辑电路,以实现更复杂的运算和控制结构。
无环图(Acyclic Graph)
无环图是一种图,其中不存在从任何顶点开始并最终返回到同一顶点的路径。在硬件电路设计中,这意味着信号的流动是单向的,从输入端到输出端没有循环或反馈路径。这是重要的,因为任何类型的反馈都可能导致不稳定或振荡,而这在设计可靠的数字电路时是不可接受的。
32位进位链加法器(RCA)
我们本可以显式地写出RCA的链,但我们也可以使用循环!
// 定义一个函数来实现32位进位链加法器
function Bit#(33) add32(Bit#(32) x, Bit#(32) y, Bit#(1) c0);
// 初始化和(sum)和进位(carry)变量
Bit#(32) s = 0;
Bit#(33) c = 0;
c[0] = c0; // 将初始进位设置为c0
// 使用循环来实现32位的加法,每次循环处理一个比特位
for (Integer i=0; i<32; i=i+1) begin
// 调用全加器fa,处理当前位的x、y及进位
Bit#(2) cs = fa(x[i],y[i],c[i]);
// 将全加器输出的和(sum)存储到s变量
// 并将进位输出存储到下一个进位位置
c[i+1] = cs[1];
s[i] = cs[0];
end
// 返回32位的结果和最高进位
return {c[32],s};
endfunction
该代码定义了一个名为add32的函数,它将两个32位的位向量x和y作为输入,并返回一个33位的结果(32位和一个进位)。这里使用了一个for循环,这个循环从0迭代到31(共32次),在每次迭代中,它都会调用一个全加器函数fa来计算对应位的和及产生的新进位。循环的每次迭代都对一个比特位的加法进行处理,并将结果存储在s变量中,进位存储在c变量中。
在此,Bit#(n)是Bluespec中表示宽度为n位的位向量类型。例如,Bit#(32)是一个32位的位向量,Bit#(1)是一个单比特。fa函数是全加器,它接受两个输入比特x[i]和y[i],以及进位c[i],然后返回一个两位数的结果,cs[0]是和,cs[1]是新的进位。
最终,函数返回的是一个33位的位向量,其中最高位是最终的进位c[32],其余32位是加法结果s。这个函数体现了硬件描述语言在设计大规模数字电路时的强大功能,尤其是当设计中涉及到重复性结构时,循环提供了一种高效且紧凑的方式来描述这种结构。
32位进位链加法器的工作原理:
一个进位链加法器由一系列的全加器组成,每个全加器都对应于输入数位向量的一个位。在每一位上,全加器会将两个输入数的相应位以及从前一位获得的进位相加。这个过程从最低位开始,逐位向高位进行,进位依次传递。
假设我们要将两个32位的二进制数X和Y相加,并且没有初始的进位输入(即c0 = 0)。我们可以用如下的伪代码来表示这个操作:
function add32(X, Y, c0)
初始化和(S)为0
初始化进位向量(C)为0,且C[0]设为c0(初始进位)
对于 i 从 0 到 31(含32位)
使用全加器对 X[i], Y[i], 和 C[i] 进行加法操作
将全加器的和输出存储到 S[i]
将全加器的进位输出存储到 C[i+1]
返回最终的和 S 和最高位的进位 C[32]
end function
具体的示例:
为了更清晰地理解,我们用两个具体的32位数来演示:
- 数字
X= 32'b1011...(32位中只有最后四位是1011,其余都是0) - 数字
Y= 32'b1100...(32位中只有最后四位是1100,其余都是0)
在Bluespec函数add32中:
-
初始化 S 和 C 为全0。
-
循环从 i=0 到 i=31:
- 第一次迭代(i=0):
X[0]= 1,Y[0]= 0,C[0](初始进位)= 0。- 全加器计算:1 + 0 + 0 = 1(和),进位 = 0。
- S[0] = 1,C[1] = 0。
- 第二次迭代(i=1):
X[1]= 1,Y[1]= 1,C[1] = 0(上一步的进位)。- 全加器计算:1 + 1 + 0 = 0(和),进位 = 1。
- S[1] = 0,C[2] = 1。
- ...以此类推,直到最后一个位。
- 第一次迭代(i=0):
-
完成循环后,我们得到最终的和 S 和最高位的进位 C[32]。
最终输出的和 S 将是两个数相加的结果,C[32] 是最高位的进位,如果这个进位为1,则意味着最终的和超出了32位,表明溢出。
请注意,实际的硬件设计中全加器会是预定义的组件,Bluespec编译器会将这些循环和函数调用转换成具体的硬件逻辑。
回到32位进位链加法器
for (Integer i = 0; i < 32; i = i + 1) begin
Bit#(2) cs = fa(x[i], y[i], c[i]);
c[i+1] = cs[1];
s[i] = cs[0];
end
展开循环后:
cs = fa(x[0], y[0], c[0]);
c[1] = cs[1];
s[0] = cs[0];
cs = fa(x[1], y[1], c[1]);
c[2] = cs[1];
s[1] = cs[0];
...
cs = fa(x[31], y[31], c[31]);
c[32] = cs[1];
s[31] = cs[0];
循环体内的cs是一个局部变量。因此,每个cs都指向一个不同的值。我们也可以将它们命名为cs0, cs1, ..., cs31。
补充解释:
在这个32位进位链加法器的例子中,for循环是用来重复执行全加器fa的计算,对于输入向量x和y的每一位,以及上一位的进位c[i]。全加器将这三个值相加,并生成两个输出:和(s[i])和新的进位(c[i+1])。
在循环中,变量cs是一个两位宽的位向量(Bit#(2)),其中cs[0]是和的结果,cs[1]是新的进位。每次迭代,cs会获取新的值,因为每次调用全加器时输入都不同。实际上,我们可以把每次迭代的cs视为不同的实体,如cs0, cs1等等。
将循环展开是硬件描述语言(HDL)常见的做法,目的是明确每个步骤中使用的具体硬件单元。这个展开过程通常是编译器在从高级硬件描述语言转换为低级硬件设计时自动执行的。展开后的结果显示了32个全加器按顺序排列,展示了从输入位到最终和位的完整路径。每个全加器处理一对输入位和进位,并产生新的和位和进位。这个过程从x[0], y[0], c[0]开始,一直到x[31], y[31], c[31],最后产生32位和向量s和最终的进位c[32]。
循环到门
这部分描绘了如何从逻辑循环创建出硬件门的过程。在这个特定的例子中,我们看到一个32位进位链加法器(Ripple-Carry Adder, RCA)是如何通过展开循环来生成的,以及每次迭代中使用的全加器(full adder, fa)如何相互连接。
在原始代码中的循环,使用全加器函数fa连续计算32位加法:
cs0 = fa(x[0], y[0], c[0]);
c[1] = cs0[1]; s[0] = cs0[0];
cs1 = fa(x[1], y[1], c[1]);
c[2] = cs1[1]; s[1] = cs1[0];
...
cs31 = fa(x[31], y[31], c[31]);
c[32] = cs31[1]; s[31] = cs31[0];
展开后的循环定义了一个无环的连接图:
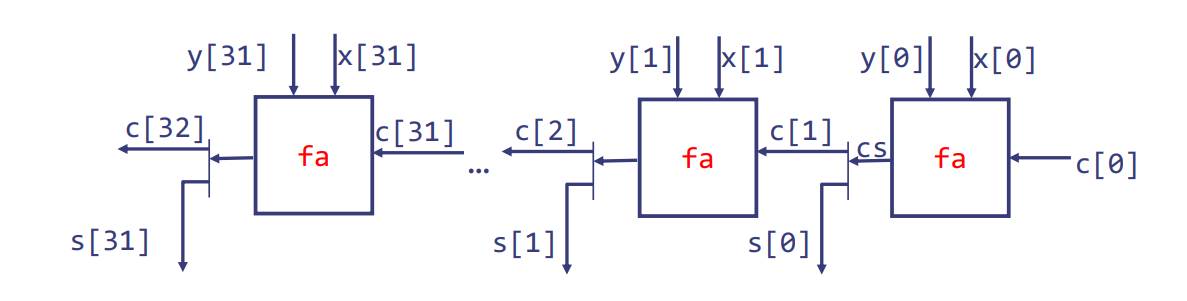
每个调用全加器fa的实例都被其实体替换。
在这个图示中,原本在循环结构中的每次迭代实际上被转换为一个全加器实体,并排列成一系列硬件门。全加器是基本的计算单元,负责两个位的加法并考虑进位。
cs0, cs1, ..., cs31是全加器产生的中间结果,其中包含和(s)和新的进位(c)。展开这个循环就意味着创建了一个无环的连接图,这是硬件实现中很重要的概念,因为硬件电路必须是无环的,以确保信号可以从输入流向输出,没有任何回环。
在这个连接图中,我们看到输入向量x和y的每一位以及进位信号c被逐个传递给相应的全加器,然后全加器产生相应位的和(s)和下一位的进位(c)。这个过程最终生成了一个32位宽的和向量s和一个额外的进位位c[32]。这种逐步计算的方式体现了进位链加法器的名称,因为每一位的计算可能依赖于前一位的计算结果,形成了一个“进位链”。
通过重复加法实现乘法
这部分展示了如何通过重复加法来实现二进制乘法操作。图中的流程展示了将一个乘数(multiplier)逐位地与另一个乘数(multiplicand)相乘的过程,这是计算机硬件中乘法器的典型实现方法。

- b 乘数(multiplicand):1101(十进制中的 13)
- a 乘数(multiplier):* 1011(十进制中的 11)
在每一步,我们根据乘数的一个比特,要么将 1101 或 0 加到结果中。
m[i] = (a[i] == 0) ? 0 : b;
在每一步我们也将m[i]向移动一个位置。注意,第一次加法是不必要的,因为它只产生了 m0。让我们再讲解一下这个重复加法的乘法过程:
- 在每一步,我们根据乘数
a当前位ai的值决定是添加被乘数b或者是 0 到暂存的乘积tp上。这是通过mi来实现的,如下所示:- 如果
ai是 1,则mi = b。 - 如果
ai是 0,则mi = 0。
- 如果
- 接着,将
mi加到tp上。 - 在下一步开始之前,我们将
mi向左移动一位。这是因为每向左移动一位相当于乘以 2(也就是说,在二进制下,相当于将数字提高一个位权重),以反映在下一步中mi所代表的值在位权重上的增加。
在上述的例子中,我们将 13 和 11 相乘:
- 在第一步,我们有
m0 = 1101(因为a0是 1),我们把m0加到tp上,得到tp = 1101。 - 然后我们需要将
m0(现在为1101)向左移动一位得到m1(现在为11010),因为我们在处理乘数的下一位。 - 接下来的每一步都重复这个过程,根据乘数的下一位决定
mi是b还是 0,然后把它加到tp上,并且在进行下一步之前将mi向左移动一位。最终结果是两个数的乘积,即二进制 10001111 或十进制 143。
整个过程中,tp 是暂存的乘积,最终是累积的结果。mi` 在每一步后会向左移动,以反映其在二进制中位权重的提高。
在硬件设计中,这个过程通常是自动化的,通过硬件乘法器电路实现,它能够快速有效地执行这些操作。这个过程也显示了乘法可以通过一系列的加法和移位操作来完成,这是计算机内部进行乘法的基础原理。
在硬件设计中,这个过程通常是自动化的,通过硬件乘法器电路实现,它能够快速有效地执行这些操作。这个过程也显示了乘法可以通过一系列的加法和移位操作来完成,这是计算机内部进行乘法的基础原理。
通过重复加法实现的乘法电路
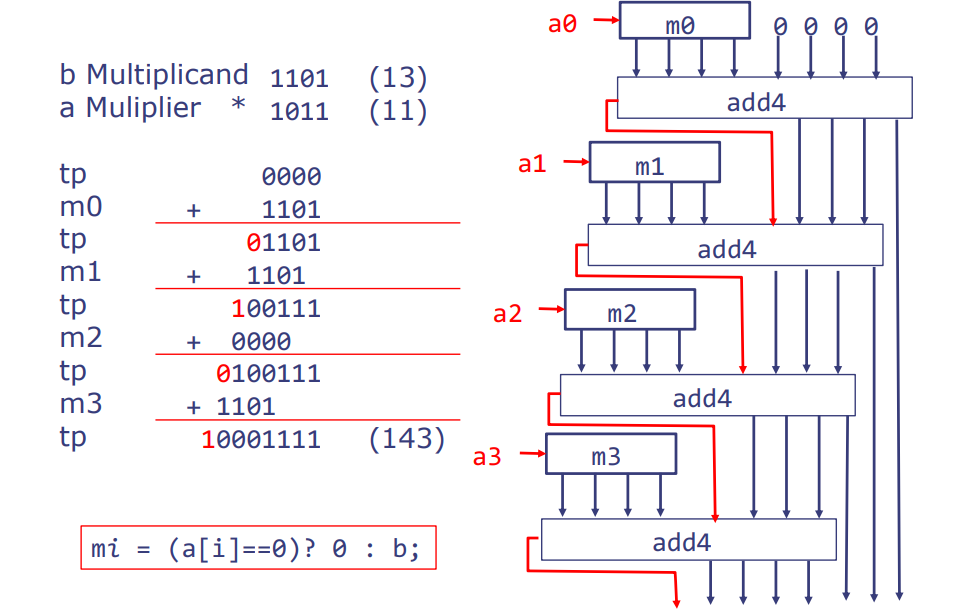
对于这个乘法运算,右侧的电路图展示了这个逻辑表达式如何在硬件中实现。每一个 mi 通过一个四位加法器(add4)与之前的 tp 相加,产生新的 tp 值。每一步的 mi 是通过检查 ai 并决定是传递 0 还是 b 来实现的。这里用到了一个选择器(multiplexer),基于 ai 的值,选择 0 或 b。
为了更好的理解,我们可以将这个过程中的每一步看作是一个迭代,每次迭代处理一个 ai 位,并更新 tp。通过在每一步将 mi 向左移位,我们确保了加法是在正确的位权重上进行的。
在乘法过程中,mi 的左移也意味着加法器处理的位置向左(即向更高的位)移动了,因此每一步得到的结果位会逐渐填充到最终结果的对应位置。这也就是为什么每次加法后的最低位可以直接成为最终结果的一部分,因为后面的加法操作会在更高位进行,不会影响到已经确定的低位结果。这个过程在硬件设计中体现出累加的乘积如何在不同的时钟周期内构建,最终形成了乘法的总和。
这个电路的设计体现了计算机组成中的一项基本概念:通过组合简单的组件(如加法器和选择器),我们能够构建出完成复杂运算的硬件结构。
组合式32位乘法器(Combinational 32-bit multiply)
// 定义一个函数,接受两个32位的输入参数a和b,返回一个64位的结果
function Bit#(64) mul32(Bit#(32) a, Bit#(32) b);
Bit#(32) tp = 0; // 定义一个临时乘积变量,初始化为0
Bit#(32) prod = 0; // 定义最终乘积变量,初始化为0
// 循环32次,实现乘法运算
for(Integer i = 0; i < 32; i = i+1) begin
Bit#(32) m = (a[i]==0)? 0 : b; // 如果乘数a的第i位为0,则m为0;否则为被乘数b
Bit#(33) sum = add32(m,tp,0); // 调用add32函数将m和tp进行加法运算,并添加0作为进位输入
prod[i] = sum[0]; // 将加法结果的最低位存储到最终乘积的第i位
tp = sum[32:1]; // 更新tp,为下一轮迭代准备
end
return {tp,prod}; // 返回最终乘积结果,64位
endfunction
这段代码展示了如何在硬件设计中通过组合逻辑实现32位的乘法器。在这里,我们使用了一个for循环来模拟乘法过程:每一次迭代中,我们检查乘数a的当前位,如果该位为1,则将被乘数b添加到临时乘积tp上;如果为0,则不添加。每次添加后,我们都将临时乘积tp向左移动一位,以便下一位的加法。这里的add32函数负责执行加法操作,并返回加法的结果和新的进位值。
分析32位乘法器
- 我们能设计一个更快的加法器吗? 答案是肯定的,通过优化加法器的设计可以减少传播延迟。
- 我们能否重用加法器电路,并减小乘法器的大小? 请继续关注,解决方案即将揭晓。
长门链(Long chains of gates):32位乘法器序列中有32个逐级传递的加法器。32位逐级传递的加法器有一个32长的门链。
思考题:32位乘法器的传播延迟是多少?
- 加法器的传播延迟通常取决于全加器(FA)的延迟。考虑到一个32位的加法器可能由32个全加器组成的链,我们需要计算这个链中每个全加器的延迟相加的结果。
在这里的分析中,重要的是要理解传播延迟的计算对于确定电路的性能至关重要。通过优化这些延迟,可以实现更快的硬件设计。
n位逐级传递加法器(n-bit Ripple-Carry Adder)
// 定义一个泛型函数,实现一个n位逐级传递加法器,输入参数是两个n位数和一个进位位
function Bit#(n+1) addN(Bit#(n) x, Bit#(n) y, Bit#(1) c0);
Bit#(n) s = 0; // 定义一个n位的和数变量,初始化为0
Bit#(n+1) c = 0; // 定义一个(n+1)位的进位变量,初始化为0
c[0] = c0; // 将输入的进位位赋给进位变量的最低位
// 循环n次,每次处理一位加法,并处理进位
for (Integer i=0; i<n; i=i+1) begin
let cs = fa(x[i],y[i],c[i]); // 调用全加器函数fa处理当前位的加法和进位
c[i+1] = cs[1]; // 将全加器返回的进位存储到进位变量的下一位
s[i] = cs[0]; // 将全加器返回的和存储到和数变量的当前位
end
return {c[n],s}; // 返回一个(n+1)位的结果,最高位是最终的进位,其余位是和数
endfunction
这部分展示了一个泛型的n位逐级传递加法器(Ripple-Carry Adder, RCA)的代码实现。
代码中的addN函数是参数化的,这意味着可以通过指定参数n的值来创建不同大小的加法器。例如,如果我们需要一个8位加法器,我们可以调用addN并将n设置为8。
遗憾的是,这段代码存在类型错误。由于类型系统的复杂性,在硬件描述语言中,这些错误可能不太直观,因此需要细心地检查以确保类型的正确性。这些错误可能包括不正确的位宽定义或错误的类型运算,如尝试对类型参数进行算数运算。
- 现在可以通过指定
n来实例化不同大小的加法器。 这展示了硬件描述语言的强大功能,可以创建可配置且重复使用的硬件组件。 - 不幸的是,这个程序中有一些微妙的类型错误 - 我们将一一解决它们。 在硬件设计中,类型错误可能会导致电路实现不正确或仿真失败,因此在实现之前需要对代码进行严格的类型检查和调试。
该加法器实现的关键点在于,它使用了循环结构来代替显式编写的长加法器链。通过这种方式,设计者可以避免代码冗余,更容易维护和更新电路设计。然而,要正确地使用这种方法,设计者需要深入理解如何在其硬件描述语言中处理类型,以及如何确保泛型代码的正确性和可重用性。
这张图片提供了一个关于Bluespec语言中类型系统的介绍。现在,让我们翻译并详细解释这些内容。
Bluespec中的类型介绍
类型(Types)
- 每个Bluespec程序中的表达式都有一个类型。
- 类型是一组值的集合,例如:
Bit#(16)// 16位宽的位向量(16是一个数值类型)Bool// 1位值代表True或FalseVector#(16,Bit#(8))// 包含16个Bit#(8)的向量
- 类型声明可以通过
#语法被其他类型参数化,比如:Bit#(n)表示n位,例如,Bit#(8),Bit#(32)等。Tuple2#(Bit#(8), Integer)表示一个由8位向量和一个整数组成的对。function Bit#(8) fname(Bit#(8) arg)表示一个函数,从Bit#(8)到Bit#(8)的值。
- 类型名称总是以大写字母开头,而变量标识符以小写字母开头。
类型同义词(Type synonyms)
typedef Bit#(8) Byte;// 8位宽的类型,称为Bytetypedef Bit#(32) Word;// 32位宽的类型,称为Wordtypedef Tuple2#(a,a) Pair#(type a);// 表示一个类型为a的元素的对typedef 32 DataSize;// 表示数据大小的数值类型typedef Bit#(DataSize) Data;// 以DataSize为大小的位向量类型,称为Data
补充解释
- 在硬件描述语言(HDL)中,类型不仅仅代表了变量可以持有的数据范围,它也对应于硬件电路中数据的宽度。例如,
Bit#(8)通常表示一个8位的寄存器或内存空间。 - 类型参数化允许设计者创建可配置的组件。例如,使用
Bit#(n),我们可以为不同的位宽生成不同大小的硬件结构,无需为每种大小编写新的代码。 - 类型同义词(Type synonyms)提高了代码的可读性和维护性。通过类型别名,设计者可以给常见的数据结构或常量定义一个更易理解的名称。
这些概念在硬件设计中非常重要,因为它们提供了对数据宽度、操作和结构的精确控制,这对于优化硬件资源和性能至关重要。使用类型系统,设计者可以减少错误,因为编译器会在类型不匹配时给出警告,从而确保电路的正确实现。
枚举类型
一种非常实用的类型概念
- 假设我们有一个变量
c,它的值可以表示三种不同的颜色- 我们可以声明变量
c的类型为Bit#(2),并采用一个约定:00代表红色,01代表蓝色,10代表绿色。
- 我们可以声明变量
- 一种更好的方式是创建一个名为
Color的新类型:typedef enum {Red, Blue, Green} Color deriving(Bits, Eq);
为什么这种方式更好?
- Bluespec编译器会自动为这三种颜色分配位表示,并提供一个函数来测试两种颜色是否相等。
- 如果你不使用“deriving”,那么你需要自己指定编码和相等性函数。
补充解释
- 使用枚举类型可以更明确地定义值的集合,这对于硬件设计尤其重要,因为它确保了信号的正确性和一致性。例如,不能错误地将代表颜色的信号与代表其他类型数据的信号混合。
- 当声明了一个枚举类型,Bluespec编译器通过
deriving关键字,可以自动为这些值生成二进制编码和相等性检测函数,这样设计者就不需要手动编写这些通常很琐碎的代码。 - 枚举类型提高了代码的可读性和可维护性,使得硬件设计的意图更加清晰,同时减少了错误的可能性。如果要比较两个颜色信号,编译器将确保它们具有相同的枚举类型,从而避免类型错误。
- 在硬件中实施类型安全(type safety)可以防止许多由于类型不匹配而可能导致的错误,这些错误可能会导致电路行为异常或设计失败。通过使用枚举,硬件设计者可以创建更加健壮和可靠的硬件系统。
枚举类型是强类型编程语言的一个重要特性,它在硬件设计语言中的使用提供了类型安全和更好的抽象,以保证电路设计的准确性和效率。
类型检查
Bluespec编译器会检查所有声明的类型是否一致使用。
function Bit#(3) fa(Bit#(1) a, Bit#(1) b, Bit#(1) c_in);
Bit#(2) ab = ha(a, b);
Bit#(2) abc = ha(ab[0], c_in);
Bit#(1) c_out = ab[1] | abc[1];
return {c_out, abc[0]};
endfunction
fa函数声明了返回类型Bit#(3),但在函数内部c_out和abc[0]组合只会产生一个Bit#(2)类型的值。编译器会标记这一错误。- 事实上,编译器可以通过推断某些类型来减少程序员的负担,而不需要显式的类型声明,这就是所谓的“let”语法。
“let”语法
function Bit#(2) fa(Bit#(1) a, Bit#(1) b, Bit#(1) c_in);
let ab = ha(a, b);
let abc = ha(ab[0], c_in);
let c_out = ab[1] | abc[1];
return {c_out, abc[0]};
endfunction
- 使用
let语法可以让编译器自动推断ab和abc的类型,这取决于ha函数的返回类型。 - "let" 语法非常方便,将在幻灯片中广泛使用。
在这个上下文中,类型检查和“let”语法提供了一个更简洁和安全的方式来描述硬件功能,这是设计硬件时减少错误的关键。例如,如果我们忘记了声明正确的位宽,或者错误地组合了不匹配的类型,类型检查就会帮助我们捕捉到这些错误,从而避免在实际硬件制作过程中造成昂贵的错误。在这种方式下,程序员可以专注于设计的逻辑部分,而类型的一致性和正确性则有编译器来保证。
在Bluespec中,类型是定义数据结构大小的一种方式。以下是对图中内容的翻译及解释:
修正类型错误
参数化的波纹进位加法器(Ripple-Carry Adder)
function Bit#(n+1) addN(Bit#(n) x, Bit#(n) y, Bit#(1) c0);
Bit#(n) s = 0;
Bit#(n+1) c = 0;
c[0] = c0;
for (Integer i=0; i<n; i=i+1) begin
let cs = fa(x[i],y[i],c[i]);
c[i+1] = cs[1];
s[i] = cs[0];
end
return {c[n],s};
endfunction
- 在这个函数中,
n是一个数值类型,并且Bluespec不允许在类型上进行算术运算,例如n+1,i<n,{c[n],s}都是非法的。
在计算机硬件设计的语境中,类型(Types)和它们在程序中的使用至关重要,因为它们决定了硬件设计中信号的宽度和操作的有效性。以下是对图中内容的翻译及解释:
valueOf(n) 对比 n
- Bluespec程序中的每个表达式都有一个类型(Type)和一个值(Value),这两者来自完全不同的领域。
- 在
Bit#(n)中的n是一个数值类型变量(numeric type variable),它存在于类型世界中。 - 有时我们需要从类型世界中使用值来进行实际计算。函数
valueOf用于从数值类型中提取整数值。- 因此,
i < n不是类型正确的,而i < valueOf(n)是类型正确的。
- 因此,
TAdd#(n, 1) 对比 n+1
- 有时我们需要在类型世界中执行与值世界中类似的操作,比如加法、乘法、基于2的对数等。
- Bluespec定义了一些特殊操作符来在类型世界中执行此类操作,例如
TAdd#(m,n)、TSub#(m,n)、TMul#(m,n)、TDiv#(m,n)、TLog#(n)、TExp#(n)、TMax#(m,n)、TMin#(m,n)等。- 因此,
Bit#(n+1)不是类型正确的,但Bit#(TAdd#(n,1))是类型正确的。
- 因此,
修正了类型错误的参数化波纹进位加法器
function Bit#(TAdd#(n,1)) addN(Bit#(n) x, Bit#(n) y, Bit#(1) c0);
Bit#(n) s = 0;
Bit#(TAdd#(n,1)) c = 0;
c[0] = c0;
let valN = valueOf(n);
for (Integer i=0; i<valN; i=i+1) begin
let cs = fa(x[i],y[i],c[i]);
c[i+1] = cs[1];
s[i] = cs[0];
end
return {c[valN],s};
endfunction
TAdd#(n,1):用于计算类型n加1的结果,因为在Bluespec中类型不能直接加上一个数值。这是一种类型运算。valueOf(n):这是一个函数,它将类型n转换为一个可以用于值运算的整数。这里,它用于循环条件,确保循环次数与类型n的值相符。addN:这个函数用于创建一个参数化的加法器,可以接受任何位宽为n的输入,并正确地计算结果。
关键点:
- 一旦定义了一个组合电路,我们就可以重复使用它来构建更大的电路。
- 由于Bluespec编译器的类型签名功能,它防止了我们以明显非法的方式连接函数和门。
- 我们可以使用循环结构和函数来表达组合电路,但所有循环在编译阶段都会被展开,所有函数都会内联。
- 高级概念:我们还可以编写参数化的电路,例如n位加法器。一旦指定了n,就会自动生成正确的电路。
最佳学习类型的方法是尝试编写一些表达式并将它们提供给编译器。
通过这样的设计,Bluespec允许硬件设计者编写灵活且可重用的电路描述,这些描述可以根据给定的参数自动生成正确宽度的信号和电路。这对于现代硬件设计中的可扩展性和模块化至关重要。
附:Bluespec中的一些类型算数运算
Bluespec是一种用于硬件设计的高级语言,它使用类型系统来表示硬件信号的宽度。在Bluespec中,信号宽度是静态类型的一部分,这样编译器在编译时就能知道每个信号的大小。这些类型操作(比如TAdd#(m,n))用于在类型层面上执行算数操作,因为在Bluespec中,你不能直接对类型进行数学运算。
以下是Bluespec中的一些类型算数运算和它们的含义:
- TAdd#(m,n):类型加法,返回一个类型,表示将m和n相加的结果。这在需要创建一个比当前类型宽度更大的新类型时非常有用。表达式对应:
Bit#(n+1) - TSub#(m,n):类型减法,返回一个类型,表示将m和n相减的结果。用于计算较小宽度类型。表达式对应:
Bit#(n-1) - TMul#(m,n):类型乘法,返回一个类型,表示m和n乘积的宽度。这对于确定乘法运算结果的位宽非常有用。表达式对应:
Bit#(m*n) - TDiv#(m,n):类型除法,返回一个类型,表示m除以n的结果宽度。用于确定除法运算的位宽。表达式对应:
Bit#(m/n) - TLog#(n):类型对数,用于计算一个类型n的对数,通常是对数基2,用于计算能表示n的二进制数的位宽。表达式对应:
Bit#(log2(n)) - TExp#(n):类型指数,用于返回2的n次幂的类型宽度。表达式对应:
Bit#(2^n) - TMax#(m,n):类型最大值,返回m和n中较大的那个类型。用于比较两个类型并获取更大的一个。表达式对应:
Bit#(max(m,n)) - TMin#(m,n):类型最小值,返回m和n中较小的那个类型。用于比较两个类型并获取较小的一个。表达式对应:
Bit#(min(m,n))
L08-Design Tradeoffs in Arithmetic Circuits
MIT 6.004 2019 L08 Design Tradeoffs in Arithmetic Circuits,由教授Arvind讲述。
这次讲座的主题为:算术电路中的设计权衡。
主要内容
- 组合逻辑讲座:
- 这是关于组合逻辑的最后一讲,之后的课程将转向时序逻辑学习,这也是一个非常有趣的话题。
- 本周四将有一次测验,已经安排了复习课程。
- 算术电路中的设计折衷:
- 硬件设计中算法的折衷是一个非常有趣的话题。设计算术电路可以说是没有穷尽的,理论家和实践者都在这个领域工作。
- 需要进行多维优化,我们希望最小化电路占用面积,同时也希望最小化延迟(即输入到输出的时间),而功率消耗则稍后在课程中讨论。
- 在选择算法时需要有高层次的理解,因为在硬件中对算法的折衷与在软件中不同。例如,有些算法可能在某些情况下效果非常好,因为我们需要更好的硬件。
- 算法在硬件设计中的应用:
- 你需要能够用一种高级描述语言表达你的算法,然后输入到编译器中生成代码。工具可以做很多优化,有时候会出现意外的结果。
- 理论上我们需要了解为什么某个算法比另一个更好,但实践中我们也需要看到这是否真的如此。
- 快速加法器的设计:
- 我们将讨论一个快速加法器的设计,这并不是一个虚构的问题。当我们设计时序电路和像RISC-V这样复杂的处理器时,我们会关心运行速度,你会发现加法器往往是拖慢速度的因素。
- 重温Ripple-Carry Adder:
- Ripple-Carry Adder在设计中很容易实现。如果试图理解它的延迟,最糟糕的情况是进位信号需要从最不重要的位一直传递到最重要的位。
- 我们使用Big O表示法(如O(n))来表示电路的延迟与操作数的数量成正比。
- Carry-Lookahead Adders(CLA):
- CLA的关键想法是将携带的链转换为树,这种转换是为了加速进位信号的生成。
- 在CLA中,我们使用generate和propagate概念,这些不依赖于进位信号的值,这给我们一个机会来组成这些进位信号。
- 最终,我们可以在对数时间内(如log n)生成所有进位信号。
- 加法器性能和面积:
- 讲座最后,讨论了不同加法器的性能和它们占用的面积。例如,与基本的Ripple-Carry Adder相比,递归的Carry Select Adder有更快的性能,但占用的面积更大。
- Carry-Lookahead Adder在面积和性能上都表现得更好,但相比于最基本的加法器,它们的面积占用显著增加。
- 这些优化的加法器有助于提升整个机器的运行速度,因为如果不够快,整个机器可能都会变慢。
- 综合总结:
- 选择正确的算法对设计至关重要。如果你的算法不好,你无法弥补一个糟糕的设计。
- Carry-Lookahead Adders可以进行O(n)数量级的加法运算,尽管付出了一些面积成本。
- 这种技术可以用来优化广泛的电路类别,因此需要深入研究这些内容,它们对你的项目也将是非常有用的。
分页知识点
算法在硬件设计中的权衡
- 每个功能都允许许多实现方式,这些方式在延迟、面积和功耗方面有着广泛的权衡。
- 选择正确的算法对于优化设计至关重要:
- 工具无法补偿效率低下的算法(在大多数情况下)。
- 这就像编程软件一样。
- 案例研究:构建一个更好的加法器。
在硬件设计中,每一个电路功能都可以通过不同的实现方法来达成,而这些不同的实现方法之间存在着一系列的权衡。例如,某些设计可能在减少电路延迟(即从输入到输出所需时间)方面更加有效,但可能需要更多的硬件面积(即占用更多的芯片空间)或者更高的功耗。相对的,其他设计可能使用更少的空间或消耗更少的能量,但在处理信号时会更慢。
关键在于选择正确的算法,这是优化硬件设计的关键步骤。正如软件开发中算法的选择对程序性能有着决定性影响一样,硬件电路设计也需要以高效的方式组织逻辑和计算过程。硬件描述语言和综合工具可以帮助设计师从高层次的电路描述中生成优化的硬件实现,但它们不能完全替代一个本身就高效的算法。如果算法设计得不好,即便是使用最先进的综合工具,也无法达到最佳的硬件性能。
级联进位加法器:简单但慢
最坏情况路径:
从LSB到MSB的进位传播,例如,将 11...111 加到 00...001 时
- \( t_{PD} = (n-1) * t_{PD,C\rightarrow CO} + t_{PD,CI\rightarrow S} \approx \Theta(n) \)
- Q(n) 读作 "n阶(order n)",告诉我们加法器的延迟与操作数的位数成线性增长关系
级联进位加法器是一种基本的数字加法器设计,它将两个n位的二进制数进行相加。在这个设计中,每一个位的进位输出(CO)都是下一个位的进位输入(CI)。由于这种设计,最坏的延迟情况发生在进位必须通过所有位传播时,例如,从最低有效位(LSB)到最高有效位(MSB)。在这种情况下,整个加法操作的时间取决于每个全加器的进位延迟时间(\( t_{PD,C\rightarrow CO} \)),乘以位数减一(因为最后一位没有下一位),再加上最后一位的和输出延迟时间(\( t_{PD,CI\rightarrow S} \))。
这里的公式 \( t_{PD} \) 表示整个加法器的传播延迟时间,大致与操作数的位数(n)成线性关系,即随着位数的增加,延迟时间线性增长。这是由大写希腊字母 Θ(Theta)所表示的,通常用来描述算法的时间复杂度。在这里,Θ(n)意味着延迟时间和操作数的位数成正比。
从硬件设计的角度来看,级联进位加法器因其简单和直观的设计而受到青睐,尤其是在位数不多的情况下。然而,在设计需要处理大量位数的高速计算硬件时,其性能可能会成为瓶颈。因此,工程师和设计师可能会探求其他类型的加法器设计,比如超前进位加法器(carry-lookahead adder),以提高性能和减少计算延迟。
渐近分析
假设某些计算需要执行 \( n^2+2n+3 \) 步骤
- 我们说它需要 \( \Theta \) (\( n^2 \))(读作“n平方阶”)步骤
- 为什么?因为 \( 2n^2 \) 总是大于 \( n^2+2n+3 \),除了几个小整数(1,2 和 3)
正式地说,\( g(n) = \Theta(f(n)) \) 当且仅当存在 \( C_2 > C_1 > 0 \),对于除了有限多个整数 \( n \geq 0 \) 外,都有 \( C_2 \cdot f(n) \geq g(n) \geq C_1 \cdot f(n) \)
- \( g(n) = O(f(n)) \)
- \( \Theta \) (…)表示两个不等式都成立;
- \( O \) (…)只表示第一个不等式成立。
解释及补充内容
在计算机科学中,渐近分析是评估算法运行效率的重要工具。它不是测量算法的实际运行时间,而是分析算法性能如何随着输入大小的增加而变化。
例如,对于一个算法,如果计算步骤的总数是输入大小 \( n \) 的二次函数,即 \( n^2+2n+3 \),我们可以用大写的 Theta(\( \Theta \) )来表示它的渐近运行时间。在这种情况下,我们关注 \( n^2 \) 项,因为它在 \( n \) 较大时主导总步骤数。当 \( n \) 足够大时,\( 2n \) 和常数 3 相比于 \( n^2 \) 变得不重要。
在这里,\( g(n) = \Theta(f(n)) \) 表示 \( g(n) \) 的增长速率和 \( f(n) \) 一致。实际上,这意味着存在常数 \( C_1 \) 和 \( C_2 \),使得 \( g(n) \) 始终在 \( C_1 \cdot f(n) \) 和 \( C_2 \cdot f(n) \) 之间。对于大多数 \( n \) 的值,\( g(n) \) 不会低于 \( C_1 \cdot f(n) \),也不会超过 \( C_2 \cdot f(n) \)。
大 O( \( O \))符号用于表示上界,即 \( g(n) = O(f(n)) \) 表示 \( g(n) \) 的增长速率不会超过 \( f(n) \) 的增长速率的某个常数倍。这通常用于最坏情况分析。
举个例子:
在渐近分析中,假设我们有一个函数 \( f(n) = n^2 + 2n + 3 \) 来表示算法或硬件电路的性能,如时间复杂度或所需步骤数。我们说这个函数是 \( O(n^2) \) 的阶,即 "order \( n^2 \)"。这里的 \( O \) 是大O符号,用于描述最坏情况的上界。
为什么是这样的?因为当 \( n \) 足够大时,\( n^2 \) 项是支配项,也就是说它对结果的影响最大。实际上,存在两个常数 \( C_1 \) 和 \( C_2 \) (其中 \( C_2 > C_1 > 0 \)),使得对于所有足够大的 \( n \),我们有:
\[ C_1 \cdot n^2 \leq n^2 + 2n + 3 \leq C_2 \cdot n^2 \]
这里的 \( g(n) = n^2 + 2n + 3 \),\( f(n) = n^2 \)。
例如,可以取 \( C_1 = 1 \) 和 \( C_2 = 4 \)。这样,对于所有足够大的 \( n \),不等式保持为真:
\[ n^2 \leq n^2 + 2n + 3 \leq 4n^2 \]
这两个不等式分别保证了 \( g(n) \) 的下界和上界。在大 \( n \) 的值时,2n 和 3 相对于 \( n^2 \) 来说不太重要,所以我们通常关注 \( n^2 \) 项。
要注意的是,\( C_1 \) 和 \( C_2 \) 的确切值并不重要,重要的是存在这样的常数使得这些不等式成立。实际中,你可能不会计算这些常数,而是知道对于大的 \( n \),主要的增长趋势是由 \( n^2 \) 决定的。
大O符号 \( O(...) \) 只保证了上界,即 \( g(n) \) 不会增长得比 \( f(n) \) 快得多。而渐近紧确界 \( \Theta(...) \) 同时保证了上界和下界,说明 \( g(n) \) 的增长率被 \( f(n) \) 紧密包围。在这个例子中,因为 \( g(n) \) 实际上就是由 \( n^2 \) 的项主导,所以我们也可以说 \( g(n) \) 是 \( \Theta(n^2) \)。
举个不一样的例子:
- 如果 \( g(n) = 100n^2 \),那么它既是 \( O(n^2) \) 也是 \( \Theta(n^2) \)。
- 如果 \( g(n) = n^2 + 10n \),那么它也是 \( O(n^2) \) 和 \( \Theta(n^2) \),因为 \( n^2 \) 项仍然是支配项。
- 如果 \( g(n) = n \log n \),那么它是 \( O(n^2) \)(因为 \( n \log n \) 的增长速度比 \( n^2 \) 慢),但它不是 \( \Theta(n^2) \),因为没有任何常数 \( C_1 \) 使得 \( C_1 \cdot n^2 \leq n \log n \) 对于所有足够大的 \( n \) 都成立。在这种情况下,\( n \log n \) 的增长率显然低于 \( n^2 \)。
因此,\( \Theta \) 通常在我们已经了解算法或电路性能的确切特性时使用,而 \( O \) 更多地用于上界分析,特别是在我们只关心不超过某种特定增长率时。
这些概念对于硬件设计同样重要,因为它们可以帮助设计者理解和预测硬件组件在处理更大规模数据时的表现。在硬件中,我们可能关心的“步骤”可能是信号在电路中传播的时间或逻辑门的切换次数,而不仅仅是算法中的计算步骤。渐近分析允许设计者预估电路设计在不同输入大小下的表现,以确定其可伸缩性和潜在的性能瓶颈。
选择加法器(CSA)牺牲面积换取速度
选择加法器(Carry-Select Adder, CSA)通过牺牲芯片面积(即硬件资源)来提高计算速度。该加法器的设计原理如下:
- 将两组输入的32位数分别划分为高16位和低16位。
- 对每一部分,分别计算两个可能的和:一个假设来自低16位的进位为0,另一个假设进位为1。
- 低16位加法器的进位输出用于选择上述两个高16位加法器结果中的正确和。
传播延迟(Propagation delay):
\[ t_{pd,32} = t_{pd,16} + t_{pd,MUX} \]
这里的 t_{pd,32} 表示32位选择加法器的传播延迟,t_{pd,16} 是16位加法器的传播延迟,t_{pd,MUX} 是多路选择器(MUX)的传播延迟。使用16位纹波进位加法器作为基础组件时,这种设计能将32位纹波进位加法器的延迟减半。
然而,这种设计有一个明显的缺点:它比纹波进位加法器消耗更多的面积。此外,宽多路选择器(Wide MUX)也会引入显著的延迟。
在这个设计中,多路选择器(MUX)指的是决定使用哪个高16位的加法器的结果的部分。具体来说,就是这个图中没有明确显示的逻辑单元,它基于低16位的结果来选择高16位加法器的输出,因此它对整个系统的速度和效率有重大影响。
Bluespec实现
标题:选择加法器以空间换取速度
选择加法器(Carry-Select Adder,CSA)利用增加硬件资源(增加芯片面积)来提高计算速度。其核心设计如下:
- 将32位的两个输入数分成两个16位的部分。
- 分别对这两部分进行计算,每部分同时考虑两种情况:一种是上一部分的进位为0,另一种是进位为1。
- 根据低16位部分的计算结果确定哪一种情况是正确的,然后选择相应的高16位部分的结果。
代码解释:
function Bit#(33) csa32(Bit#(32) a, Bit#(32) b, Bit#(1) c);
let csL = add16(a[15:0], b[15:0], c); // 计算低16位
let csU = (csL[16] == 0) ? add16(a[31:16], b[31:16], 0) // 如果低16位的进位为0,就使用0作为高16位的进位
: add16(a[31:16], b[31:16], 1); // 如果低16位的进位为1,就使用1作为高16位的进位
return {csU,csL[15:0]}; // 返回33位结果,包括32位和及进位位
endfunction
这段代码定义了一个33位的函数csa32,它接收两个32位的输入a和b,以及一个进位输入c。它首先计算低16位,并根据低16位的计算结果确定高16位的进位。然后,根据这个进位计算高16位,最终返回一个33位的结果,其中包括32位的和以及最终的进位。
注意:“We can use any type of adder, including CSA”意味着这个选择加法器可以使用不同类型的加法器作为其组成部分,包括但不限于CSA自身。
这种设计是在硬件设计中权衡决策的一个典型例子,反映出在计算速度、硬件资源(面积)和功耗之间必须作出的选择。通过这个例子,可以更好地理解计算机硬件设计中这些权衡的重要性。
递归式选择加法器
相对于绘制图形,编写选择加法器(Carry-Select Adder)的代码要更简单一些。以下是函数定义和递归应用的示例:
function Bit#(33) csa32(Bit#(32) a, Bit#(32) b, Bit#(1) c);
let csL = csa16(a[15:0], b[15:0], c); // 对低16位进行加法操作
let csU = (csL[16] == 0) ? csa16(a[31:16], b[31:16], 0) // 如果低16位没有进位,则高16位不使用进位
: csa16(a[31:16], b[31:16], 1); // 如果低16位有进位,则高16位使用进位
return {csU, csL[15:0]}; // 返回33位结果,包括32位和及进位位
endfunction
这个csa32函数计算两个32位数a和b的和,加上一个进位c。它首先使用一个16位的选择加法器csa16来计算a和b的低16位部分的和,然后根据低16位的结果决定高16位是否应该加上进位。最后,它返回一个33位的结果,包括32位的和及最终的进位。
其他的加法器函数可以类似地被定义:
// `csa16`:16位选择加法器。
function Bit#(17) csa16(Bit#(16) a, Bit#(16) b, Bit#(1) c);
// `csa8`:8位选择加法器。
function Bit#(9) csa8(Bit#(8) a, Bit#(8) b, Bit#(1) c);
// `csa4`:4位选择加法器。
function Bit#(5) csa4(Bit#(4) a, Bit#(4) b, Bit#(1) c);
// `csa2`:2位选择加法器。
function Bit#(3) csa2(Bit#(2) a, Bit#(2) b, Bit#(1) c);
// 让csa2使用全加器fa而不是csa1
// 这意味着在最底层我们可以使用一个简单的全加器,而不是继续递归下去
例如,csa16函数就像csa32函数一样,但处理的是16位数。这些函数可以通过递归调用来实现不同位数的加法操作。注意,这些函数也可以互相调用,例如,csa2可以使用csa1,这反映出了硬件设计中的模块化和复用性。
最后一行注释提到让csa2使用fa(全加器)而不是csa1,意味着在最基本的级别上,选择加法器可以简化为使用全加器来完成加法操作,而非继续递归下去。这种设计可以在编写硬件描述语言时通过函数调用和参数传递的方式清晰地表达出复杂硬件的结构。通过这样的递归定义,我们能够构建一个灵活的加法器,它能够根据不同的位宽要求来适配并最终形成一个完整的加法逻辑。
选择加法器(CSA)分析
- 进位延迟\( t_{PD,n} \) 符合 Θ(log n) 的时间复杂度,但是会导致额外的硬件开销。
- 面积计算:
- csa32 = 3 csa16 + mux17
- csa16 = 3 csa8 + mux9
- csa8 = 3 csa4 + mux5
- csa4 = 3 csa2 + mux3
- csa2 = 3 fa + mux2
- fa = 5 门(gates)
- muxn = 3n+1 门(gates)
- csa32总门数:
- 243 fa + 81 mux2 + 27 mux3 + 9 mux5 + 3 mux9 + mux17
- 总共 2339 门(gates)
- 即:
- csa32相当于3个csa16和一个17输入的多路选择器(mux17)。
- csa16相当于3个csa8和一个9输入的多路选择器(mux9)。
- csa8相当于3个csa4和一个5输入的多路选择器(mux5)。
- csa4相当于3个csa2和一个3输入的多路选择器(mux3)。
- csa2相当于3个全加器(fa)和一个2输入的多路选择器(mux2)。
- 每个全加器(fa)由5个基本门构成。
- 每个多路选择器(mux)由3n+1个基本门构成。
- csa32总计需要:
- 243个全加器门 + 81个2输入多路选择器门 + 27个3输入多路选择器门 + 9个5输入多路选择器门 + 3个9输入多路选择器门 + 1个17输入多路选择器门,总计2339个基本门。
- 尽管许多电路部分是重复的,但是通过编译器的布尔逻辑优化,有可能减少电路的整体大小。例如,许多全加器(fa)可能会接收相同的输入信号。
备注:“32位的传统脉波进位加法器(RCA)的面积是32个全加器,即32×5 = 160个基本门。”
这里的分析重点在于量化CSA相对于传统加法器如RCA的设计差异。CSA虽然速度更快,但牺牲了更多的硬件资源(面积),并且通常会带来更多的复杂性。分析结果表明,尽管初看上去CSA的门数非常高,但是通过编译器优化,最终的硬件资源占用可能会减少,这说明优化和合成阶段在硬件设计中起着关键作用。
超前进位加法器(CLAs)
- 超前进位加法器能够在Θ(log n)的时间复杂度内计算出所有的进位位。
- 核心思想:将进位计算的链转换为树形结构。
- 将一系列的关联操作(例如,与(AND)、或(OR)、异或(XOR))转换为树形结构通常较为简单。
- 但如何用这种方法处理进位呢?
这部分展示的是超前进位加法器(CLA)的基本概念和设计。CLAs的设计优化了进位的生成,通过创建一种逻辑,将连续的进位操作转换为树形结构,这样可以显著地减少计算每一位进位所需的时间。
传统的加法器(如图中的全加器FA)从最低有效位(Least Significant Bit, LSB)开始逐位进行加法运算,并且可能需要等待前一位的进位,从而产生所谓的“脉冲进位”(ripple-carry),这在高位宽数据路径中可能导致较高的延迟。
而CLA采用超前进位生成逻辑(Carry Generation Logic)来克服这个问题。这种逻辑预先计算可能的进位,而不必等待前一位的结果,允许加法器在对数时间内完成运算,即使在高位宽操作中也是如此。这种方法能够实现快速的加法运算,但代价是需要更多的硬件资源来实现这种复杂的进位预测逻辑。
简而言之,CLA通过在加法器的设计中引入更复杂的硬件逻辑,以空间换取时间,从而加快计算速度。
全加器Full Adder
全加器是一个数字电路中的基础组件,它可以计算三个二进制数的和:两个加数A和B,以及来自低位的进位Cin。其输出是一个二进制和S和一个进位Cout。
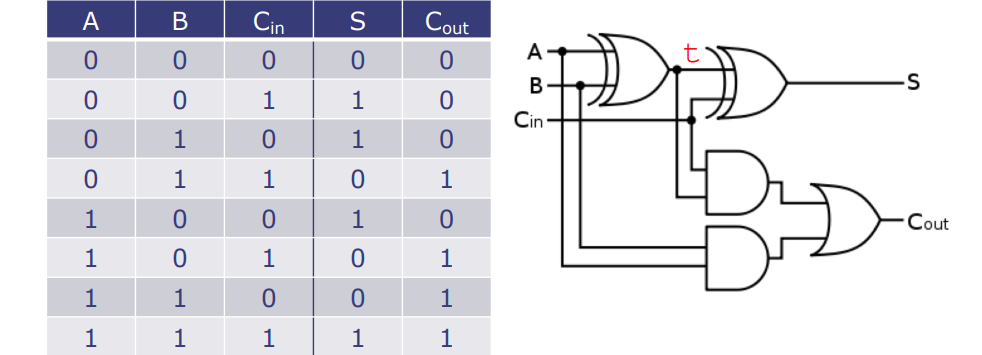
布尔方程式
- 二进制和S可以用如下布尔方程式表示(图中 S = 1 的情况): $$ S = (\neg A \cdot \neg B \cdot Cin) + (\neg A \cdot B \cdot \neg Cin) + (A \cdot \neg B \cdot \neg Cin) + (A \cdot B \cdot Cin) $$
- 进位Cout可以用如下布尔方程式表示(图中 Cout = 1 的情况): $$ Cout = (\neg A \cdot B \cdot Cin) + (A \cdot \neg B \cdot Cin) + (A \cdot B \cdot \neg Cin) + (A \cdot B \cdot Cin) $$
优化后
对布尔方程式进行优化后,我们得到更简洁的表示方式:
- 设定中间变量t为A和B的异或结果(A XOR B),表示为:\( t = A \oplus B \)
- 和S等于t和Cin的异或结果(t XOR Cin),表示为:\( S = t \oplus Cin \)
- 进位Cout等于中间变量t和Cin的与结果(t AND Cin)与A和B的与结果(A AND B)的或运算结果,表示为:\( Cout = t \cdot Cin + A \cdot B \)
图中显示了全加器的逻辑电路图,其中的各个逻辑门(如与门、或门和非门)用于实现上述布尔方程式。电路中标记为t的线是A和B的异或门的输出,这一输出同时用于计算S和Cout。电路的设计显示了如何通过组合基本的逻辑门来实现全加器的功能。全加器是组成复杂加法器(如前面提到的CLA)的基础元素。
继续优化
这里的方程实际上是以逻辑表达式的形式表示这个加法过程的。为了更直观地说明:
-
S(和)实际上是A、B、Cin的异或(XOR)操作,因为异或操作可以表示加法中的不带进位的和。具体来说,如果只有一个1(或者三个1),S将为1;如果有两个或者零个1,S将为0。
使用XOR逻辑可以简化表达式: $$ S = A \oplus B \oplus Cin $$
这表示S是A、B、Cin三者之间的异或结果。
-
Cout(进位)是在下面情况之一发生时产生的:
- A和B都是1(不管Cin),因为1+1在二进制中等于10,意味着和是0,进位是1。
- A和Cin都是1(B不重要),或者B和Cin都是1(A不重要);这表示进位来自之前的加法。
进位的逻辑表达式是: $$ Cout = (A \cdot B) + (A \cdot Cin) + (B \cdot Cin) $$
这意味着只要两个输入中至少有两个是1,就会产生一个进位。
这样,我们就能正确地表示全加器的逻辑功能,并在实际硬件或逻辑模拟中进行实现。
优化步骤
全加器的和(S)和进位(Cout)输出的优化过程如下(公式参见 L6附录):
- 和的计算:
- 原始表达式: $$ S = (\neg a \cdot \neg b \cdot C_{in}) + (\neg a \cdot b \cdot \neg C_{in}) + (a \cdot \neg b \cdot \neg C_{in}) + (a \cdot b \cdot C_{in}) $$
- 通过对项进行简化和合并,得到: $$ S = (\neg (a \oplus b) \cdot C_{in}) + (a \oplus b) \cdot \neg C_{in} $$
- 这可以进一步简化为: $$ S = a \oplus b \oplus C_{in} $$
- 这表明和(S)是输入A、B以及进位输入(Cin)的异或(XOR)结果。
- 进位的计算:
- 原始表达式: $$ C_{out} = (a \cdot b) + (\neg a \cdot b \cdot C_{in}) + (a \cdot \neg b \cdot C_{in}) + (a \cdot b \cdot \neg C_{in}) $$
- 两两合并简化到: $$ C_{out} = (a \oplus b) \cdot C_{in} + a \cdot b $$
- 另外$$ C_{out} = (a + b) \cdot C_{in} + a \cdot b $$这也是正确的表达方式,这是因为如果a和b都为1,那么不管Cin的值,Cout都将是1(表示生成了一个进位)。另一方面,如果a和b中只有一个为1,那么Cout将等于Cin的值(表示进位被传递)。
- 共享常见子表达式:
- 通过将A和B的异或运算定义为变量t: $$ t = a \oplus b $$
- 我们可以用t来简化和S和进位Cout的表达式: $$ S = t \oplus C_{in} $$ $$ C_{out} = t \cdot C_{in} + a \cdot b $$
- 这样,我们就能够使用更少的逻辑门来实现全加器的功能,因为我们避免了重复计算相同的子表达式。
以上就是全加器的优化步骤,这些步骤展示了如何将布尔逻辑方程通过代数简化来优化,从而减少所需的逻辑门数量,降低硬件复杂度。这在设计更高效的算术电路时非常重要。
进位生成与传播
进位输出 \( C_{\text{out}} \) 由两部分组成:一个部分通过 AND 运算生成进位,另一个部分通过异或运算和输入进位 \( C_{\text{in}} \) 传播进位:
\( C_{\text{out}} = (a \cdot b) + (a \oplus b) \cdot C_{\text{in}} \)
- 生成进位(generates a carry):当输入 a 和 b 都为 1 时,AND 运算 \( a \cdot b \) 的结果为 1,表示无论输入进位 \( C_{\text{in}} \) 的值如何,都会产生一个进位。
- 传播进位(propagates a carry):当输入 a 和 b 异或的结果为 1 时,表示如果存在输入进位 \( C_{\text{in}} \),则会将其传播到输出进位。
我们可以定义两个参数 g 和 p,以简化表达式:
\( C_{\text{out}} = g + p \cdot C_{\text{in}} \)
其中:
-
g (代表 generate) = \( a \cdot b \)
-
p (代表 propagate) = \( a \oplus b \)
-
当 g=1 时,\( C_{\text{out}} = 1 \)(全加器 FA 生成了一个进位)
-
当 p=1 且 g=0 时,\( C_{\text{out}} = C_{\text{in}} \)(全加器 FA 传播了进位)
注意 g 和 p 的值不依赖于 \( C_{\text{in}} \),这意味着我们可以预先计算出一个组合逻辑单元能否生成或传播进位,而不需要考虑实际的进位输入值。这在设计加法器时是非常有用的优化,它可以让我们预先处理进位的生成和传播,从而加速整个加法过程。在实际的硬件设计中,我们可以使用 g 和 p 来设计更高效的进位查找逻辑,这能够显著减少加法器的延迟,尤其是在设计大位宽的加法器时。
分层构成的进位生成与传播
这张图展示了如何通过分层方式组合全加器(FA)的进位生成(g)与进位传播(p)逻辑。
进位输出 \( C_{\text{out}} \) 定义为: \[ C_{\text{out}} = g + p \cdot C_{\text{in}} \] 其中,g 为生成进位(a 和 b 的 AND 运算),p 为传播进位(a 和 b 的 XOR 运算)。
对于更高一级的全加器组合:
- \( C_H \) 表示高半部分的进位输出。
- \( C_L \) 表示低半部分的进位输出。
- \( g_H \) 和 \( p_H \) 分别表示高半部分的进位生成和传播。
- \( g_L \) 和 \( p_L \) 分别表示低半部分的进位生成和传播。
高半部分的进位 \( C_H \) 可以使用以下表达式计算: \[ C_H = g_H + p_H \cdot C_L \] \( C_L \) 是低半部分的进位输出,它本身可以通过 \( g_L \) 和 \( p_L \) 以及输入进位 \( C_{\text{in}} \) 表示:
\[ C_L = g_L + p_L \cdot C_{\text{in}} \]
将 \( C_L \) 的表达式代入 \( C_H \) 的表达式中,我们得到: \[ C_H = g_H + p_H \cdot (g_L + p_L \cdot C_{\text{in}}) \] \[ = g_H + p_H \cdot g_L + p_H \cdot p_L \cdot C_{\text{in}} \]
其中,\( g_{HL} \) 和 \( p_{HL} \) 表示两个半部分组合后的整体进位生成和传播: \[ g_{HL} = g_H + p_H \cdot g_L \] \[ p_{HL} = p_H \cdot p_L \]
通过这种方式,我们可以从底层的全加器开始,逐步构建一个多层次的进位生成与传播网络,这样就能够以对数时间复杂度 \( O(\log n) \) 计算所有的进位值,而不是线性时间 \( O(n) \),从而大大提高加法器的计算效率。在实际的硬件设计中,这种方法特别适合实现大位数的加法器,因为它可以显著减少计算延迟。这种方法的核心是对进位传播路径的优化,通过减少必须顺序计算的全加器数量来减少总体延迟。
时间复杂度 \( O(\log n) \)
正是因为这种“一半一半”的分割方法,我们才能实现对数 \( O(\log n) \) 的延迟。这个过程可以这样理解:
在一个普通的线性进位传播加法器(比如传统的串行进位加法器)中,每一位的进位可能需要等待前一位的进位计算完成才能进行,因此最坏情况下的延迟是线性的,与位数 \( n \) 成正比。
然而,在分层的进位查找加法器(Carry-Lookahead Adder, CLA)中,加法器的设计允许我们并行地计算进位生成(g)和进位传播(p)。我们不需要等待每个全加器序列的进位计算完成,因为可以同时计算多个加法器的进位。
具体来说:
- 我们首先对每个全加器计算其自身的进位生成(g)和传播(p)。
- 然后我们将两个全加器组合起来,创建一个新的级别,这个级别能够在不知道实际进位值的情况下,预测两个加法器组合后的进位生成和传播情况。
- 我们继续将这些组合起来的加法器对合并,每次合并我们都减少一半需要考虑的加法器数量。
- 经过 \( \log n \) 次合并后(因为每次合并都减少一半,所以合并的次数是对数级别的),我们可以计算出最高位的进位值。
每一层的合并都可以并行处理,这就是为什么总体的进位计算可以在对数时间内完成的原因。这种方法显著减少了需要顺序处理的进位数量,因而大大减少了总体的计算延迟,尤其在处理大位数加法时特别有效。
合并的进行
合并是从低位到高位进行的,但它是通过层次化的方法从全部位数开始,每次分一半进行的。具体步骤如下:
-
局部计算:首先对每一对输入位(A和B)进行操作,计算每一位的进位生成(g)和进位传播(p)。
-
逐级合并:然后从最低位开始,对每一对相邻的全加器计算它们的进位生成和传播。这个过程不需要前一位的计算结果,因为进位生成和传播可以独立于实际的进位信号计算得到。
-
分层递归:合并的过程是递归进行的。首先是相邻的两位,然后是四位,八位,直至达到全部位数。每一级合并都减少了需要考虑的组数,即每一步都合并了前一步的输出。
-
对数层级:这个合并过程会形成一个对数级的树状结构,每层都合并前一层的输出,直到最顶层。由于每次合并都将组数减半,所以总的层数是 \( \log n \)。
例如,对于32位加法器,我们首先计算每一位的g和p,然后合并0和1位、2和3位,依此类推,形成16组。接着,我们将这16组再合并成8组,然后是4组,2组,最后是1组。每一步的合并都可以并行进行,所以整个进位计算的延迟是对数级别的,大致是 \( \log n \)。这种方法允许快速地计算出所有位的进位值,而不必等待每一位的串行进位计算完成。
CLA构建模块

步骤1:生成单独的g和p信号
- 对于输入位a和b,产生进位生成(g)和进位传播(p)信号。
- 公式:g = a · b (表示只有当两个输入位都是1时,才会生成一个进位)
- 公式:p = a ⊕ b (表示如果任一输入位是1,那么进位可能会传播)
这一步生成的是每一位独立的进位生成和传播信号。这两个信号描述了每一位相对于进位的行为:生成信号g表明这一位是否会无条件地生成一个进位;传播信号p表明这一位是否会根据其输入的进位(Cin)传递进位。
步骤2:合并相邻的g和p信号
- 使用合并函数(GP),将相邻全加器的g和p信号合并。
- 公式:
g_ik = g_ij + p_ij · g_(i-1)k(表示在第j位至第k位间,进位是否会被生成) - 公式:
p_ik = p_ij · p_(i-1)k(表示在第j位至第k位间,进位是否会被连续传播)
这一步合并了相邻全加器的进位生成和传播信号,用于计算整个段的进位行为。如果g_ij是1或者p_ij和g_(i-1)k都是1,则g_ik会是1;如果p_ij和p_(i-1)k都是1,那么p_ik会是1。这样就可以知道整个段是否会生成进位或者是否会传播一个进位。
步骤3:生成单独的进位信号
- 使用进位函数(C),根据组合后的g和p信号,计算每一位的实际进位(Ci)。
- 公式:
c_i = g_ij + p_ij · c_(j-1)(表示第i位的进位是否会被生成或传播)
这一步是实际生成每一位的进位信号。它利用了上一步计算出的组合进位生成和传播信号。如果g_ij是1或者p_ij和c_(j-1)都是1,那么c_i将会是1。
这里的g和p是在不考虑前一位进位的情况下独立计算的,而最终的c_i会考虑前一位的进位。注意,这些步骤展示了如何使用组合逻辑来快速生成全加器链中所有位的进位,这是CLA的核心原理。而Brent-Kung CLA是这种类型加法器的一个变种,它特别针对于优化硬件实现进行了设计。
解释【g_ik = g_ij + p_ij · g_(i-1)k】 和 【p_ik = p_ij · p_(i-1)k 】
这两个方程同上一部分的:
\[ g_{HL} = g_H + p_H \cdot g_L \] \[ p_{HL} = p_H \cdot p_L \]
g_ik = g_ij + p_ij · g_(i-1)k 和 p_ik = p_ij · p_(i-1)k 这两个方程是通过逻辑推理得出的,它们描述了如何结合两组进位生成(g)和进位传播(p)信号来计算一个更大范围的加法器块。
-
g_ik = g_ij + p_ij · g_(i-1)k- 这个方程说明了从第k位到第i位全加器段的合成进位生成信号(g_ik)是如何计算的。
g_ij表示从第j位到第i位间的进位生成信号。p_ij表示从第j位到第i位间的进位传播信号。g_(i-1)k表示从第k位到第(i-1)位间的进位生成信号。- 如果第j位到第i位间可以生成一个进位(即
g_ij为1),则整个从第k位到第i位的段也能生成一个进位(即g_ik为1)。 - 如果从第j位到第i位的段不能自己生成进位但能传播一个进位(即
p_ij为1),并且从第k位到第(i-1)位的段能生成一个进位(即g_(i-1)k为1),那么这个进位会被传播到第i位(也使得g_ik为1)。
-
p_ik = p_ij · p_(i-1)k- 这个方程描述了从第k位到第i位全加器段的合成进位传播信号(p_ik)如何计算。
p_ij和p_(i-1)k分别代表从第j位到第i位和从第k位到第(i-1)位的进位传播信号。- 只有当两个段都能传播进位(即两个
p信号都为1),合成的段才能完全传播一个来自更低位的进位(即p_ik为1)。
简单来说,这两个方程基于以下逻辑原则:
- 如果一个段能生成进位,或者能传播进位且前一段能生成进位,则整个段可以生成进位。
- 如果两个相连的段都能传播进位,则整个段也可以传播进位。
通过这样递归地组合小段的g和p信号,可以在对数时间内为整个加法器计算进位,这是CLA加速进位计算过程的关键所在。
生成和组合gp信号
总结构建进位查找加法器(CLA)的过程,我们通过以下步骤来生成和组合进位生成(g)和进位传播(p)信号:
-
初步生成g和p信号:对于加法器中的每一对输入位
a_i和b_i,我们首先计算各自的进位生成信号g_i(如果a_i和b_i都为1,则g_i为1,表示这一对位会产生一个进位)和进位传播信号p_i(如果a_i或b_i为1,则p_i为1,表示这一对位会传递一个进位)。 -
组合相邻的g和p信号:接着,我们使用逻辑门电路组合相邻的g和p信号。这些逻辑门电路被称为GP单元。例如,
gp_54表示第5位到第4位之间的g和p信号被组合起来,如此类推。 -
层次化地合并g和p信号:我们通过一系列的GP单元,层次化地合并g和p信号。每个GP单元接受两组g和p信号作为输入,并输出一组新的g和p信号。这一过程从单个比特的g和p信号开始,逐渐扩展到整个加法器。在图中,我们可以看到g和p信号如何被分层组合,最终得到了
gp_70,它包含了所有输入位的进位生成和传播信息。
进位生成
- C单元:棕色的C单元代表进位生成逻辑,它根据
gp信号和来自下一位的进位信号C_in来确定当前位的进位C_i。例如,最底层的C单元将会根据最低位的gp信号和输入进位C_in来生成进位C_0。 - 进位传播:这些C单元将进位信号向上传播给更高位的C单元。例如,
C_0将作为C_1生成单元的输入进位信号
延迟计算:
延迟的增长方式与位数的关系:Θ(log n)是算法复杂度表示法,指出随着输入位数n的增加,计算进位信号的延迟按对数规模增长。这意味着,虽然加法器的位数增加,但通过这种层次化组合方法,增加的延迟远远小于线性增长。具体来说,对于一个n位的加法器,这个延迟大约是log2(n)级别的,因为每一层的GP单元可以并行处理,减少了总体的延迟。
应用说明:
- 在实际应用中,这种对数级的延迟显著提高了计算速度,尤其是在处理多位加法器时。
- 生成的进位信号会被传递到一排全加器(FA)中,这些全加器使用进位信号和输入位来生成最终的和位。
- CLA的这种设计让我们能够实现快速的二进制加法运算,特别适用于高性能计算和数字系统设计中。
CLA设计要点
- 存在多种CLA设计,本课中展示的是Brent-Kung CLA。
- 还有其他类型的CLA设计,例如Kogge-Stone等。
- 每种类型都有不同的变体,例如,通过使用更高基数的树来减少深度。
这种技术不仅适用于加法器:它能够在Θ(log n)的延迟下计算任何一维二进制递归,例如比较器、优先级编码器等。
综合结果概述
本表格呈现了Brian Wheatman进行的几种不同加法器在综合后的结果,以及一个总结。这些结果反映了不同加法器设计在时间优化和空间优化方面的性能差异。
加法器综合比较:
- 基本门与扩展门:对于每种加法器,表格提供了两种优化方式的结果:一种针对时间优化(Time Opt),另一种针对空间优化(Space Opt)。"Basic gates"表示使用基本逻辑门综合,"Ext gates"表示使用扩展逻辑门(可能包括更复杂的逻辑功能)综合。
-
Ripple-Carry Adder (RCA):级联进位加法器在基本门综合下,门的数量为413个,面积为295微米平方,延迟为742皮秒。使用扩展门综合可以看到,面积和延迟有所减少,但仍高于专为时间或空间优化的设计。
-
Recursive Carry-Select Adder:递归进位选择加法器的门数、面积和延迟在不同优化下有明显差异。时间优化的扩展门综合版本在延迟上显著减少至226皮秒,但面积增加。
-
Kogge-Stone Adder:Kogge-Stone加法器是一种并行前缀加法器,对延迟和面积都进行了优化。特别是在时间优化的扩展门综合版本中,它的延迟进一步减少至167皮秒,面积也有所减少。
总结:
-
算法选择的重要性:正确选择算法对于设计优质的数字电路至关重要,工具只能帮助到一定程度。例如,虽然综合工具可以对电路进行一定程度的优化,但如果算法本身设计不佳,最终的硬件实现效果也会受到限制。
-
进位查找加法器的性能:进位查找加法器(Carry-lookahead adders,简称CLAs)在时间复杂度为Θ(log n)的情况下完成加法操作,尽管这会带来一些面积成本。这种技术可以用来优化广泛的电路类别,例如比较器、优先级编码器等,展示了它在多种硬件设计中的应用潜力。